 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Pretrained Cross-Lingual Language Models via Self-Labeled Word Alignment
Paper and Code
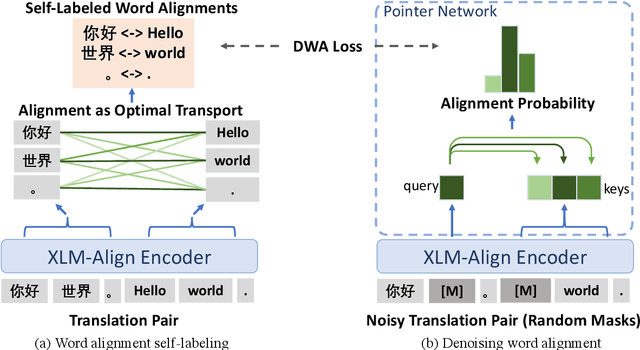
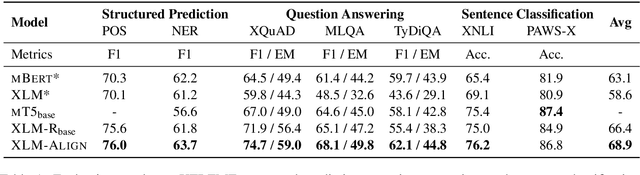
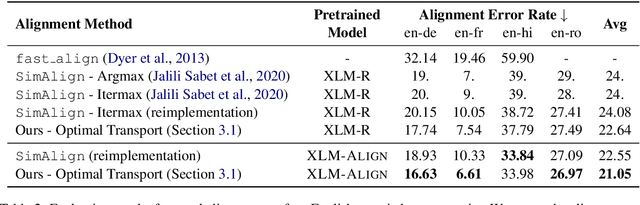
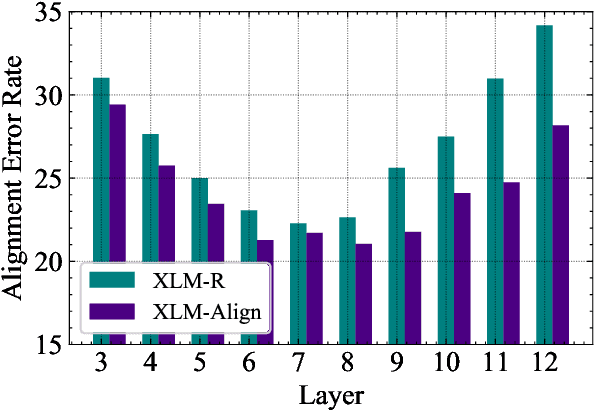
The cross-lingual language models are typically pretrained with masked language modeling on multilingual text or parallel sentences. In this paper, we introduce denoising word alignment as a new cross-lingual pre-training task. Specifically, the model first self-labels word alignments for parallel sentences. Then we randomly mask tokens in a bitext pair. Given a masked token, the model uses a pointer network to predict the aligned token in the other language. We alternately perform the above two steps in an expectation-maximization manner. Experimental results show that our method improves cross-lingual transferability on various datasets, especially on the token-level tasks, such as question answering, and structured prediction. Moreover, the model can serve as a pretrained word aligner, which achieves reasonably low error rates on the alignment benchmarks. The code and pretrained parameters are available at https://github.com/CZWin32768/XLM-Align.