 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Sparse Expert Models and Beyond
Paper and Code
Jun 14, 2021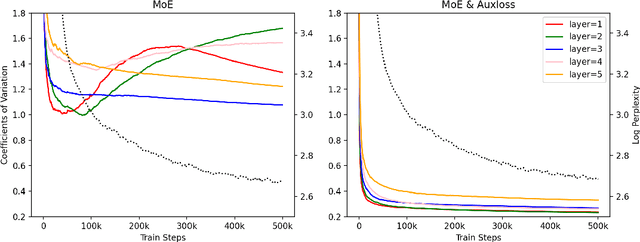

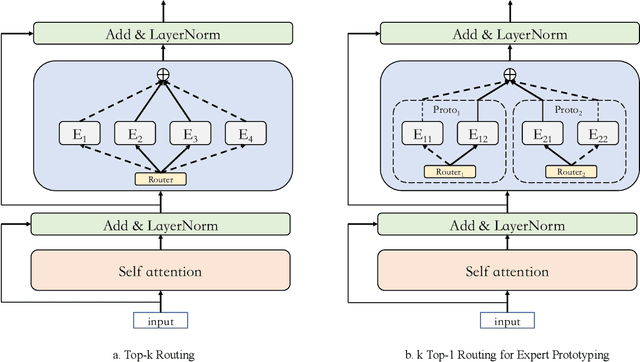
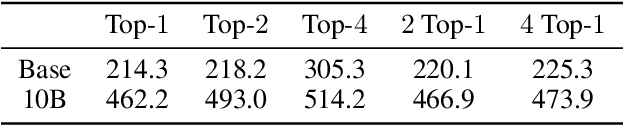
Mixture-of-Experts (MoE) models can achieve promising results with outrageous large amount of parameters but constant computation cost, and thus it has become a trend in model scaling. Still it is a mystery how MoE layers bring quality gains by leveraging the parameters with sparse activation. In this work, we investigate several key factors in sparse expert models. We observe that load imbalance may not be a significant problem affecting model quality, contrary to the perspectives of recent studies, while the number of sparsely activated experts $k$ and expert capacity $C$ in top-$k$ routing can significantly make a difference in this context. Furthermore, we take a step forward to propose a simple method called expert prototyping that splits experts into different prototypes and applies $k$ top-$1$ routing. This strategy improves the model quality but maintains constant computational costs, and our further exploration on extremely large-scale models reflects that it is more effective in training larger models. We push the model scale to over $1$ trillion parameters and implement it on solely $480$ NVIDIA V100-32GB GPUs, in comparison with the recent SOTAs on $2048$ TPU cores. The proposed giant model achieves substantial speedup in convergence over the same-size baseline.