 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Relation Alignment for Calibrated Cross-modal Retrieval
Paper and Code
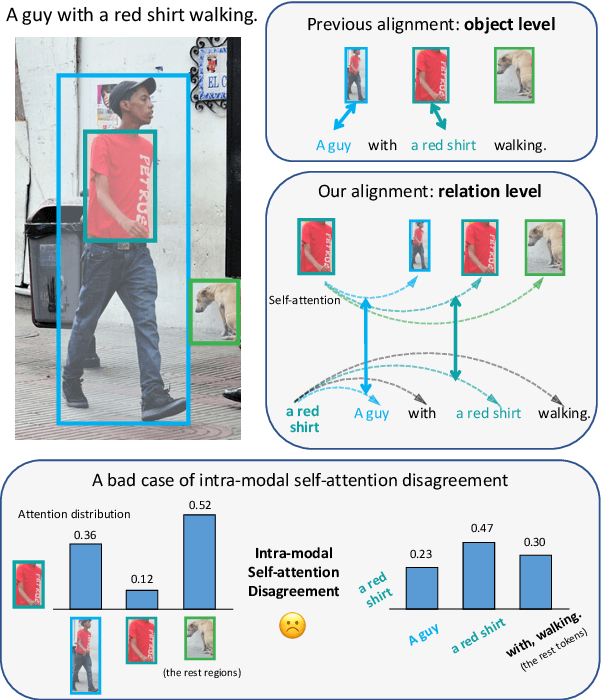
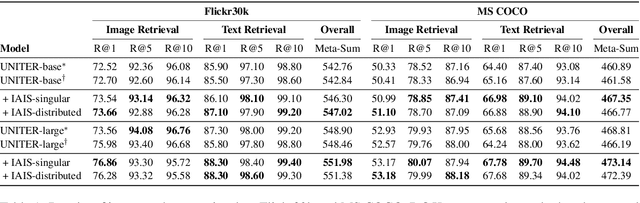
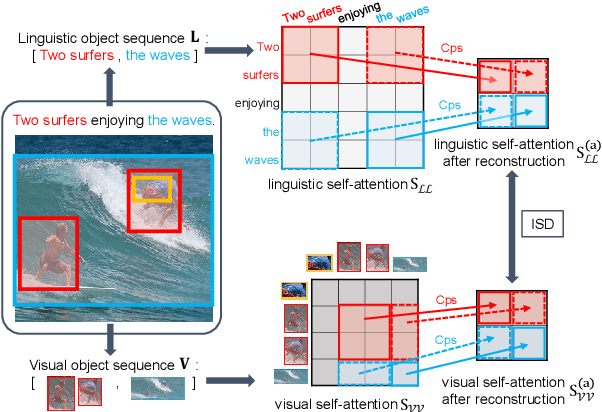
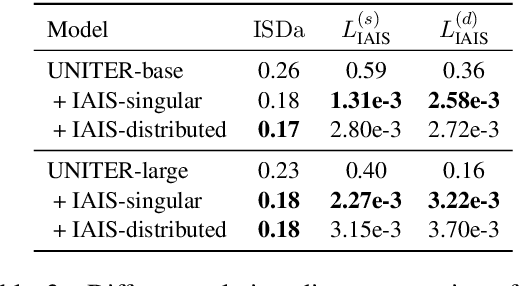
Despite the achievements of large-scale multimodal pre-training approaches, cross-modal retrieval, e.g., image-text retrieval, remains a challenging task. To bridge the semantic gap between the two modalities, previous studies mainly focus on word-region alignment at the object level, lacking the matching between the linguistic relation among the words and the visual relation among the regions. The neglect of such relation consistency impairs the contextualized representation of image-text pairs and hinders the model performance and the interpretability. In this paper, we first propose a novel metric, Intra-modal Self-attention Distance (ISD), to quantify the relation consistency by measuring the semantic distance between linguistic and visual relations. In response, we present Inter-modal Alignment on Intra-modal Self-attentions (IAIS), a regularized training method to optimize the ISD and calibrate intra-modal self-attentions from the two modalities mutually via inter-modal alignment. The IAIS regularizer boosts the performance of prevailing models on Flickr30k and MS COCO datasets by a considerable margin, which demonstrates the superiority of our approach.