 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-centric Relation Segmentation: Dataset and Solution
Paper and Code
May 25, 2021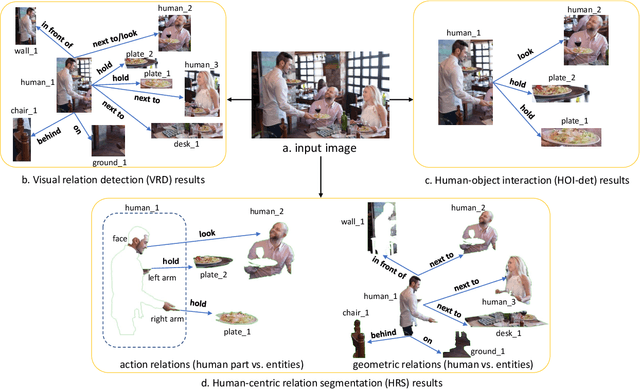

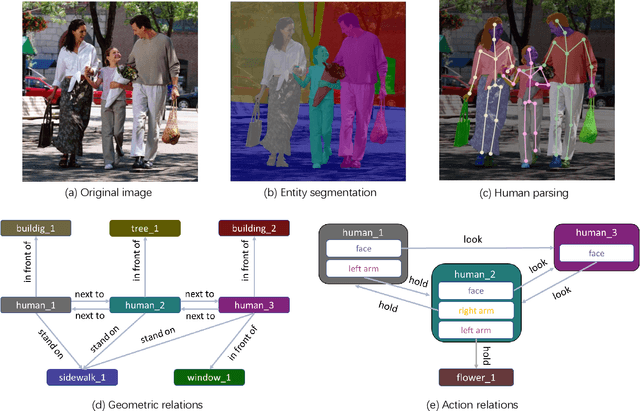
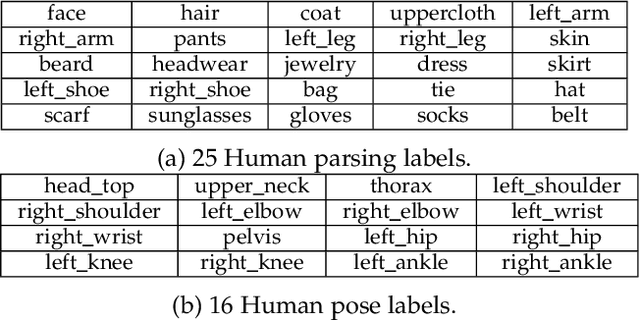
Vision and language understanding techniques have achieved remarkable progress, but currently it is still difficult to well handle problems involving very fine-grained details. For example, when the robot is told to "bring me the book in the girl's left hand", most existing methods would fail if the girl holds one book respectively in her left and right hand. In this work, we introduce a new task named human-centric relation segmentation (HRS), as a fine-grained case of HOI-det. HRS aims to predict the relations between the human and surrounding entities and identify the relation-correlated human parts, which are represented as pixel-level masks. For the above exemplar case, our HRS task produces results in the form of relation triplets <girl [left hand], hold, book> and exacts segmentation masks of the book, with which the robot can easily accomplish the grabbing task. Correspondingly, we collect a new Person In Context (PIC) dataset for this new task, which contains 17,122 high-resolution images and densely annotated entity segmentation and relations, including 141 object categories, 23 relation categories and 25 semantic human parts. We also propose a Simultaneous Matching and Segmentation (SMS) framework as a solution to the HRS task. I Outputs of the three branches are fused to produce the final HRS results. Extensive experiments on PIC and V-COCO datasets show that the proposed SMS method outperforms baselines with the 36 FPS inference speed.