 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVSR: A Unified Framework for Document Layout Analysis combining Vision, Semantics and Relations
Paper and Code
May 13, 2021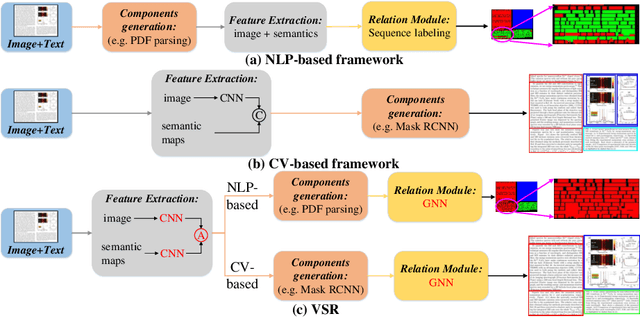
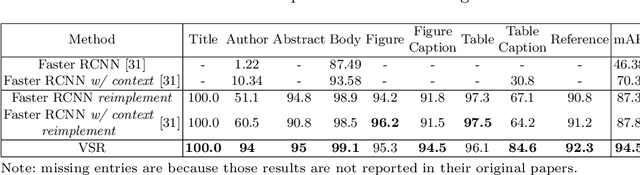
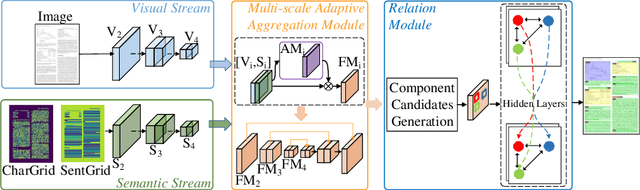
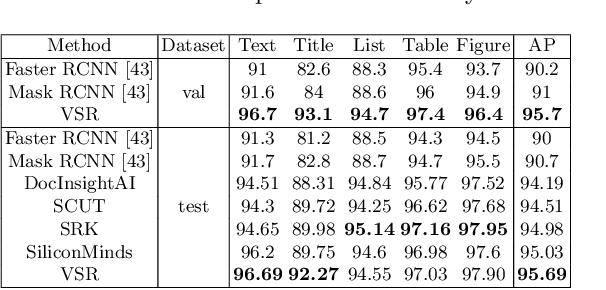
Document layout analysis is crucial for understanding document structures. On this task, vision and semantics of documents, and relations between layout components contribute to the understanding process. Though many works have been proposed to exploit the above information, they show unsatisfactory results. NLP-based methods model layout analysis as a sequence labeling task and show insufficient capabilities in layout modeling. CV-based methods model layout analysis as a detection or segmentation task, but bear limitations of inefficient modality fusion and lack of relation modeling between layout components. To address the above limitations, we propose a unified framework VSR for document layout analysis, combining vision, semantics and relations. VSR supports both NLP-based and CV-based methods. Specifically, we first introduce vision through document image and semantics through text embedding maps. Then, modality-specific visual and semantic features are extracted using a two-stream network, which are adaptively fused to make full use of complementary information. Finally, given component candidates, a relation module based on graph neural network is incorported to model relations between components and output final results. On three popular benchmarks, VSR outperforms previous models by large margins. Code will be released soon.