 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Long-Tailed Classification from Instance Level
Paper and Code
Apr 13, 2021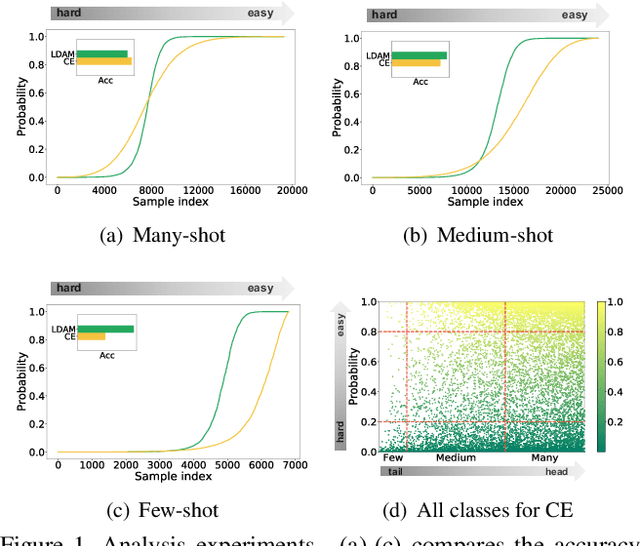
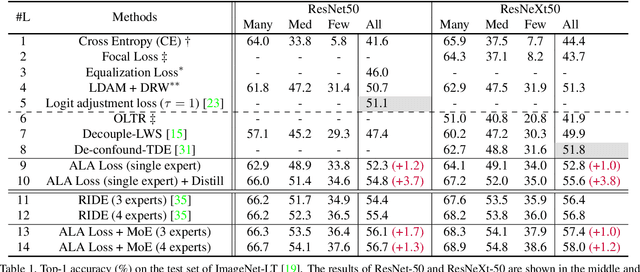
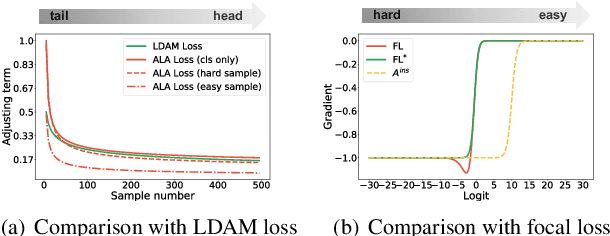

Data in the real world tends to exhibit a long-tailed label distribution, which poses great challenges for neural networks in classification. Existing methods tackle this problem mainly from the coarse-grained class level, ignoring the difference among instances, e.g., hard samples vs. easy samples. In this paper, we revisit the long-tailed problem from the instance level and propose two instance-level components to improve long-tailed classification. The first one is an Adaptive Logit Adjustment (ALA) loss, which applies an adaptive adjusting term to the logit. Different from the adjusting terms in existing methods that are class-dependent and only focus on tail classes, we carefully design an instance-specific term and add it on the class-dependent term to make the network pay more attention to not only tailed class, but more importantly hard samples. The second one is a Mixture-of-Experts (MoE) network, which contains a multi-expert module and an instance-aware routing module. The routing module is designed to dynamically integrate the results of multiple experts according to each input instance, and is trained jointly with the experts network in an end-to-end manner.Extensive experiment results show that our method outperforms the state-of-the-art methods by 1% to 5% on common long-tailed benchmarks including ImageNet-LT and iNaturalist.