 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHalf-Real Half-Fake Distillation for Class-Incremental Semantic Segmentation
Paper and Code
Apr 02, 2021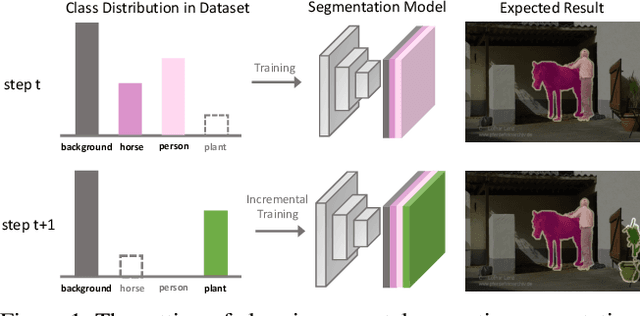
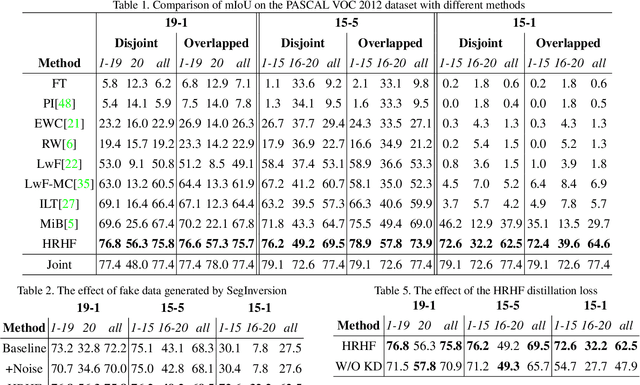
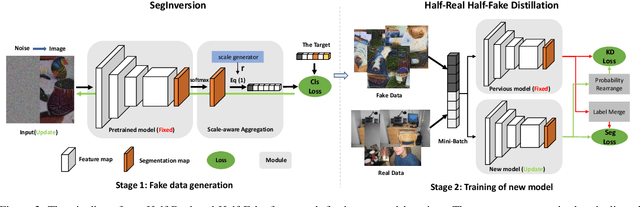

Despite their success for semantic segmentation, convolutional neural networks are ill-equipped for incremental learning, \ie, adapting the original segmentation model as new classes are available but the initial training data is not retained. Actually, they are vulnerable to catastrophic forgetting problem. We try to address this issue by "inverting" the trained segmentation network to synthesize input images starting from random noise. To avoid setting detailed pixel-wise segmentation maps as the supervision manually, we propose the SegInversion to synthesize images using the image-level labels. To increase the diversity of synthetic images, the Scale-Aware Aggregation module is integrated into SegInversion for controlling the scale (the number of pixels) of synthetic objects. Along with real images of new classes, the synthesized images will be fed into the distillation-based framework to train the new segmentation model which retains the information about previously learned classes, whilst updating the current model to learn the new ones. The proposed method significantly outperforms other incremental learning methods and obtains state-of-the-art performance on the PASCAL VOC 2012 and ADE20K datasets. The code and models will be made publicly available.