 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormal vs. Adversarial: Salience-based Analysis of Adversarial Samples for Relation Extraction
Paper and Code
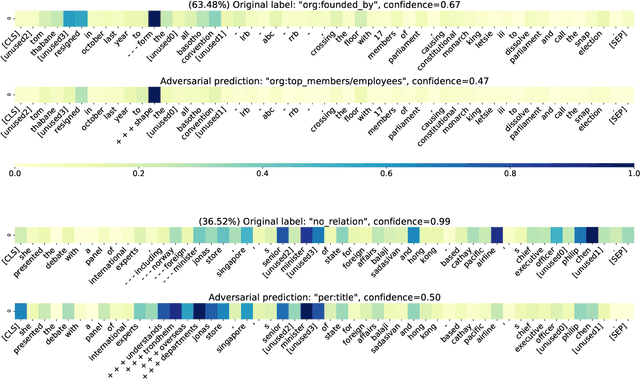
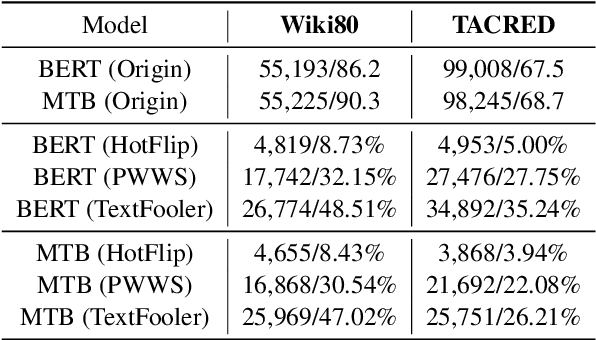
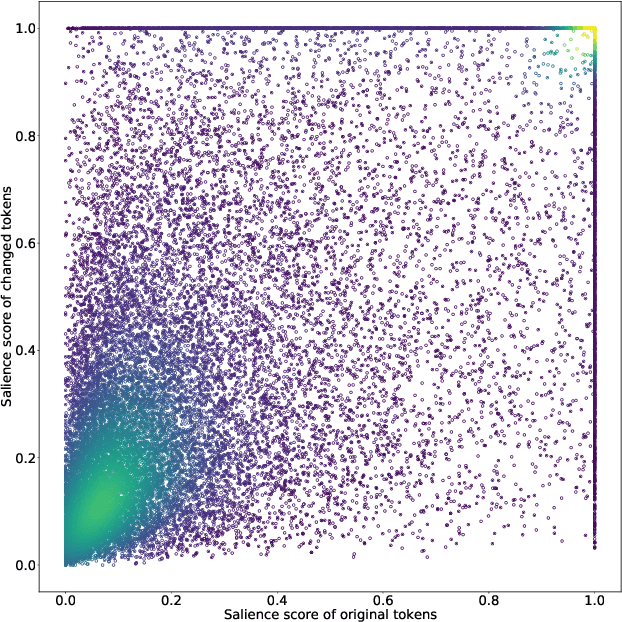
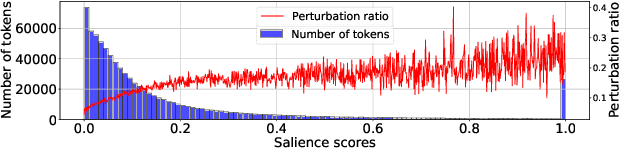
Recent neural-based relation extraction approaches, though achieving promising improvement on benchmark datasets, have reported their vulnerability towards adversarial attacks. Thus far, efforts mostly focused on generating adversarial samples or defending adversarial attacks, but little is known about the difference between normal and adversarial samples. In this work, we take the first step to leverage the salience-based method to analyze those adversarial samples. We observe that salience tokens have a direct correlation with adversarial perturbations. We further find the adversarial perturbations are either those tokens not existing in the training set or superficial cues associated with relation labels. To some extent, our approach unveils the characters against adversarial samples. We release an open-source testbed, "DiagnoseAdv".