 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePart2Whole: Iteratively Enrich Detail for Cross-Modal Retrieval with Partial Query
Paper and Code
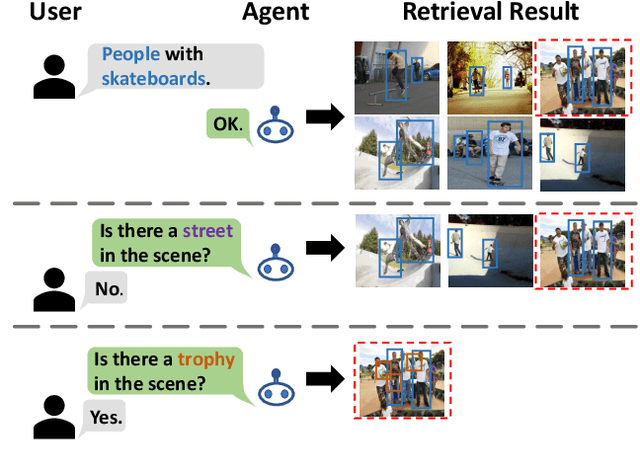

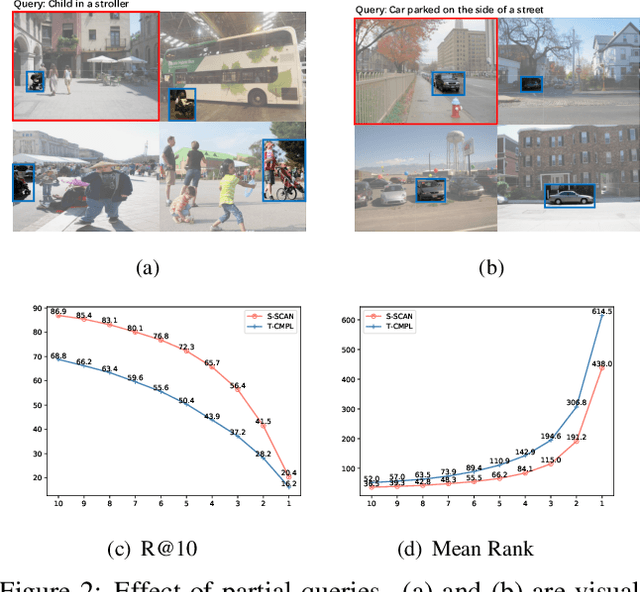
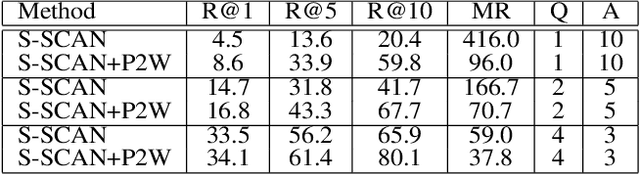
Text-based image retrieval has seen considerable progress in recent years. However, the performance of existing methods suffers in real life since the user is likely to provide an incomplete description of a complex scene, which often leads to results filled with false positives that fit the incomplete description. In this work, we introduce the partial-query problem and extensively analyze its influence on text-based image retrieval. We then propose an interactive retrieval framework called Part2Whole to tackle this problem by iteratively enriching the missing details. Specifically, an Interactive Retrieval Agent is trained to build an optimal policy to refine the initial query based on a user-friendly interaction and statistical characteristics of the gallery. Compared to other dialog-based methods that rely heavily on the user to feed back differentiating information, we let AI take over the optimal feedback searching process and hint the user with confirmation-based questions about details. Furthermore, since fully-supervised training is often infeasible due to the difficulty of obtaining human-machine dialog data, we present a weakly-supervised reinforcement learning method that needs no human-annotated data other than the text-image dataset. Experiments show that our framework significantly improves the performance of text-based image retrieval under complex scenes.