 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLGRIM: Hierarchical Value Learning for Large-scale Exploration in Unknown Environments
Paper and Code
Feb 10, 2021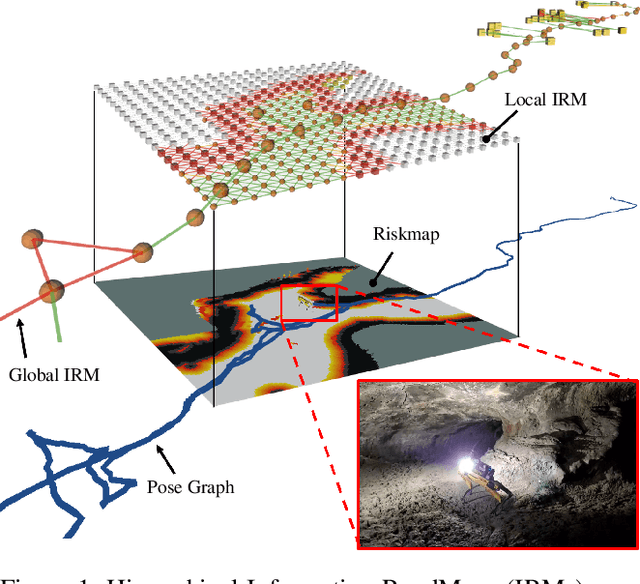
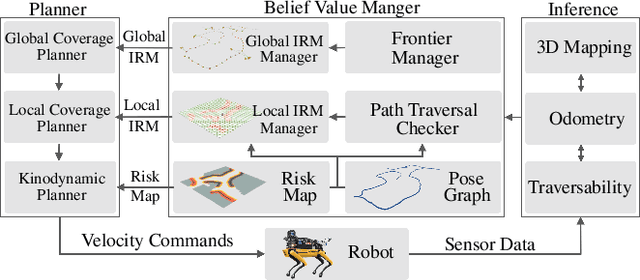
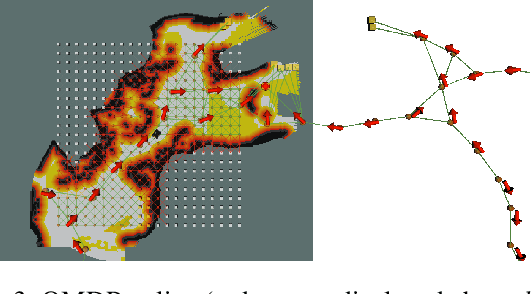
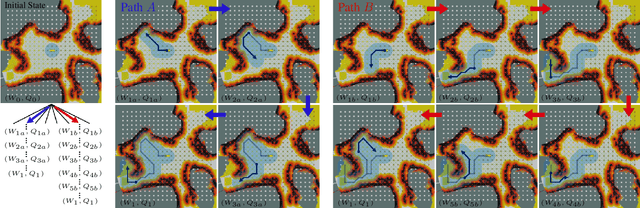
In order for a robot to explore an unknown environment autonomously, it must account for uncertainty in sensor measurements, hazard assessment, localization, and motion execution. Making decisions for maximal reward in a stochastic setting requires learning values and constructing policies over a belief space, i.e., probability distribution of the robot-world state. Value learning over belief spaces suffer from computational challenges in high-dimensional spaces, such as large spatial environments and long temporal horizons for exploration. At the same time, it should be adaptive and resilient to disturbances at run time in order to ensure the robot's safety, as required in many real-world applications. This work proposes a scalable value learning framework, PLGRIM (Probabilistic Local and Global Reasoning on Information roadMaps), that bridges the gap between (i) local, risk-aware resiliency and (ii) global, reward-seeking mission objectives. By leveraging hierarchical belief space planners with information-rich graph structures, PLGRIM can address large-scale exploration problems while providing locally near-optimal coverage plans. PLGRIM is a step toward enabling belief space planners on physical robots operating in unknown and complex environments. We validate our proposed framework with a high-fidelity dynamic simulation in diverse environments and with physical hardware, Boston Dynamics' Spot robot, in a lava tube.