 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn The Consistency Training for Open-Set Semi-Supervised Learning
Paper and Code
Jan 19, 2021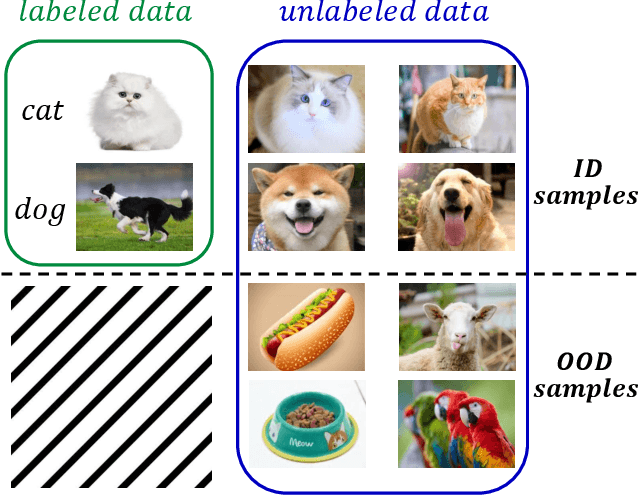
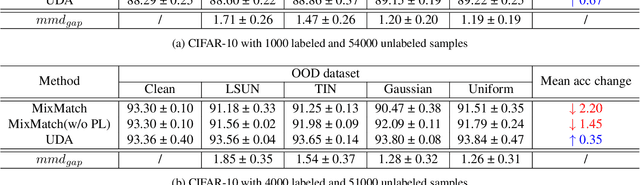


Conventional semi-supervised learning (SSL) methods, e.g., MixMatch, achieve great performance when both labeled and unlabeled dataset are drawn from the same distribution. However, these methods often suffer severe performance degradation in a more realistic setting, where unlabeled dataset contains out-of-distribution (OOD) samples. Recent approaches mitigate the negative influence of OOD samples by filtering them out from the unlabeled data. Our studies show that it is not necessary to get rid of OOD samples during training. On the contrary, the network can benefit from them if OOD samples are properly utilized. We thoroughly study how OOD samples affect DNN training in both low- and high-dimensional spaces, where two fundamental SSL methods are considered: Pseudo Labeling (PL) and Data Augmentation based Consistency Training (DACT). Conclusion is twofold: (1) unlike PL that suffers performance degradation, DACT brings improvement to model performance; (2) the improvement is closely related to class-wise distribution gap between the labeled and the unlabeled dataset. Motivated by this observation, we further improve the model performance by bridging the gap between the labeled and the unlabeled datasets (containing OOD samples). Compared to previous algorithms paying much attention to distinguishing between ID and OOD samples, our method makes better use of OOD samples and achieves state-of-the-art results.