 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Level Collaborative Transformer for Image Captioning
Paper and Code
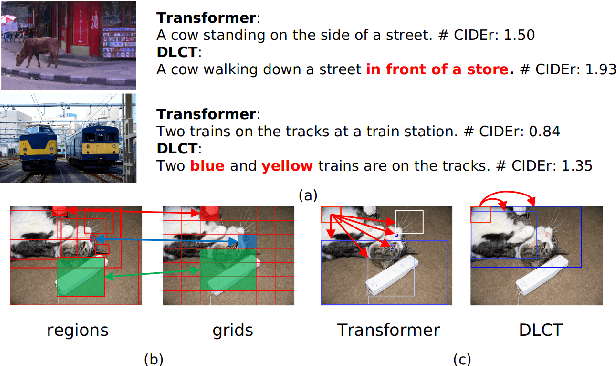
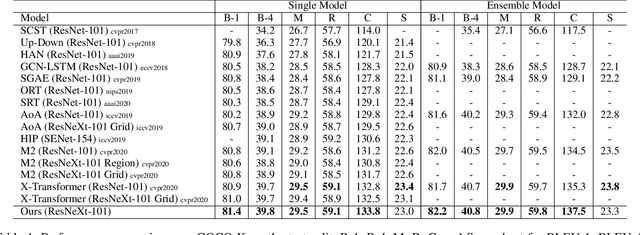
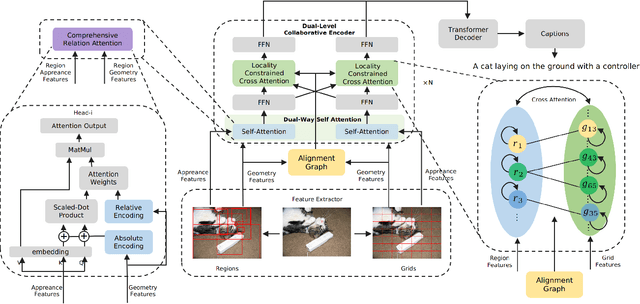
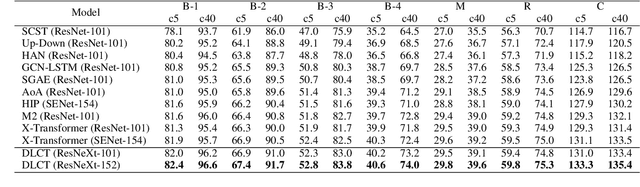
Descriptive region features extracted by object detection networks have played an important role in the recent advancements of image captioning. However, they are still criticized for the lack of contextual information and fine-grained details, which in contrast are the merits of traditional grid features. In this paper, we introduce a novel Dual-Level Collaborative Transformer (DLCT) network to realize the complementary advantages of the two features. Concretely, in DLCT, these two features are first processed by a novelDual-way Self Attenion (DWSA) to mine their intrinsic properties, where a Comprehensive Relation Attention component is also introduced to embed the geometric information. In addition, we propose a Locality-Constrained Cross Attention module to address the semantic noises caused by the direct fusion of these two features, where a geometric alignment graph is constructed to accurately align and reinforce region and grid features. To validate our model, we conduct extensive experiments on the highly competitive MS-COCO dataset, and achieve new state-of-the-art performance on both local and online test sets, i.e., 133.8% CIDEr-D on Karpathy split and 135.4% CIDEr on the official split. Code is available at https://github.com/luo3300612/image-captioning-DLCT.