 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Robustness by More Coverage: Adversarial Training with Mixup Augmentation for Robust Fine-tuning
Paper and Code
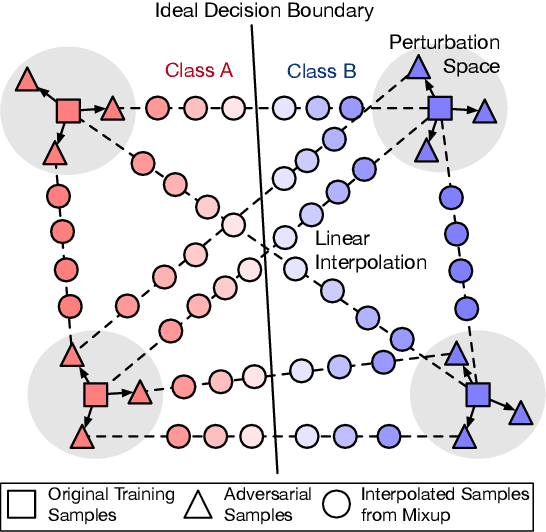
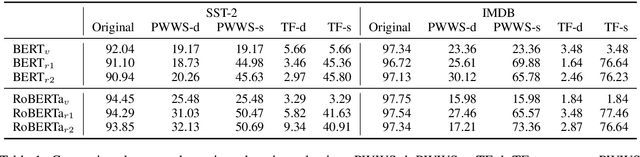
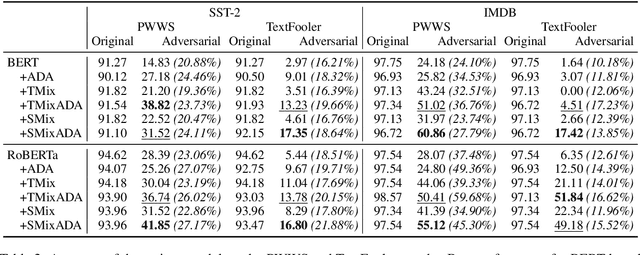
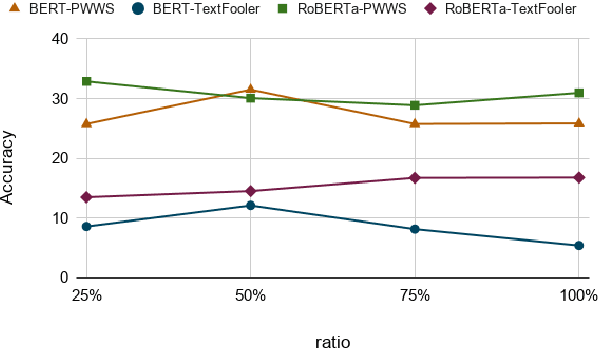
Pre-trained language models (PLMs) fail miserably on adversarial attacks. To improve the robustness, adversarial data augmentation (ADA) has been widely adopted, which attempts to cover more search space of adversarial attacks by adding the adversarial examples during training. However, the number of adversarial examples added by ADA is extremely insufficient due to the enormously large search space. In this work, we propose a simple and effective method to cover much larger proportion of the attack search space, called Adversarial Data Augmentation with Mixup (MixADA). Specifically, MixADA linearly interpolates the representations of pairs of training examples to form new virtual samples, which are more abundant and diverse than the discrete adversarial examples used in conventional ADA. Moreover, to evaluate the robustness of different models fairly, we adopt a challenging setup, which dynamically generates new adversarial examples for each model. In the text classification experiments of BERT and RoBERTa, MixADA achieves significant robustness gains under two strong adversarial attacks and alleviates the performance degradation of ADA on the original data. Our source codes will be released to support further explorations.