 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Named Entity Recognition: A Comprehensive Study
Paper and Code
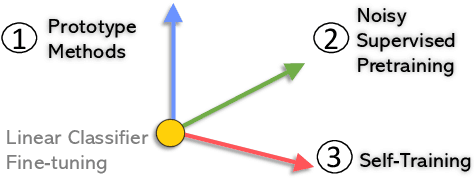

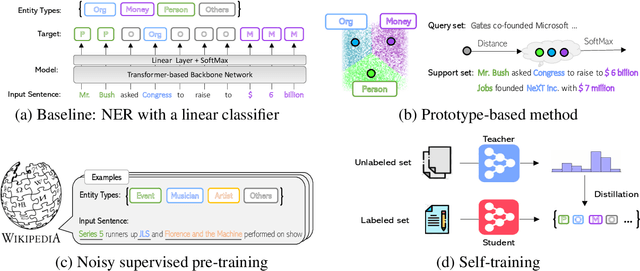
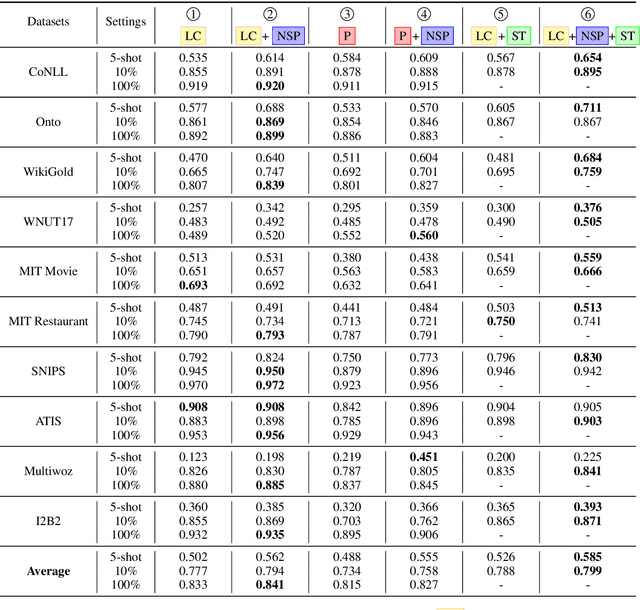
This paper presents a comprehensive study to efficiently build named entity recognition (NER) systems when a small number of in-domain labeled data is available. Based upon recent Transformer-based self-supervised pre-trained language models (PLMs), we investigate three orthogonal schemes to improve the model generalization ability for few-shot settings: (1) meta-learning to construct prototypes for different entity types, (2) supervised pre-training on noisy web data to extract entity-related generic representations and (3) self-training to leverage unlabeled in-domain data. Different combinations of these schemes are also considered. We perform extensive empirical comparisons on 10 public NER datasets with various proportions of labeled data, suggesting useful insights for future research. Our experiments show that (i) in the few-shot learning setting, the proposed NER schemes significantly improve or outperform the commonly used baseline, a PLM-based linear classifier fine-tuned on domain labels; (ii) We create new state-of-the-art results on both few-shot and training-free settings compared with existing methods. We will release our code and pre-trained models for reproducible research.