 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMT in TREC-COVID Round 2: Mitigating the Generalization Gaps from Web to Special Domain Search
Paper and Code
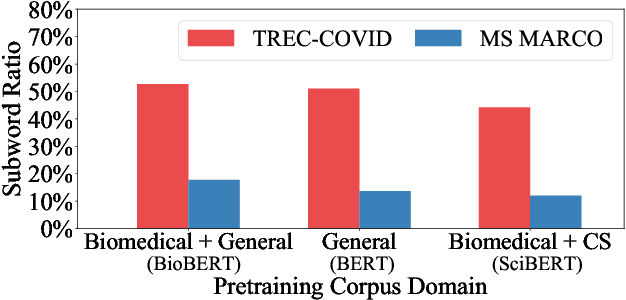

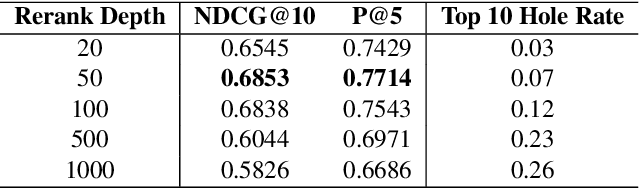
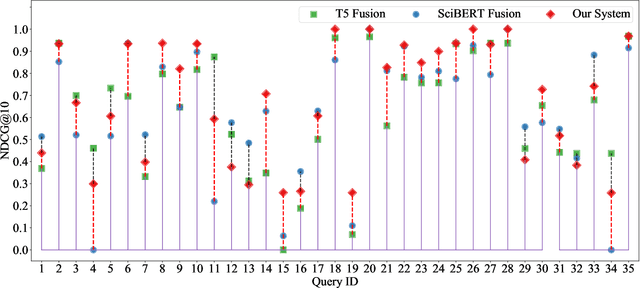
Neural rankers based on deep pretrained language models (LMs) have been shown to improve many information retrieval benchmarks. However, these methods are affected by their the correlation between pretraining domain and target domain and rely on massive fine-tuning relevance labels. Directly applying pretraining methods to specific domains may result in suboptimal search quality because specific domains may have domain adaption problems, such as the COVID domain. This paper presents a search system to alleviate the special domain adaption problem. The system utilizes the domain-adaptive pretraining and few-shot learning technologies to help neural rankers mitigate the domain discrepancy and label scarcity problems. Besides, we also integrate dense retrieval to alleviate traditional sparse retrieval's vocabulary mismatch obstacle. Our system performs the best among the non-manual runs in Round 2 of the TREC-COVID task, which aims to retrieve useful information from scientific literature related to COVID-19. Our code is publicly available at https://github.com/thunlp/OpenMatch.