Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDST: Successive Decoding for Speech-to-text Translation
Paper and Code
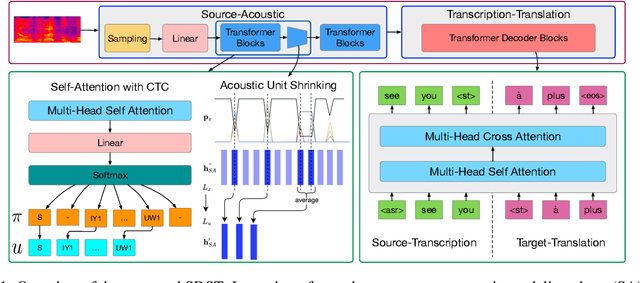

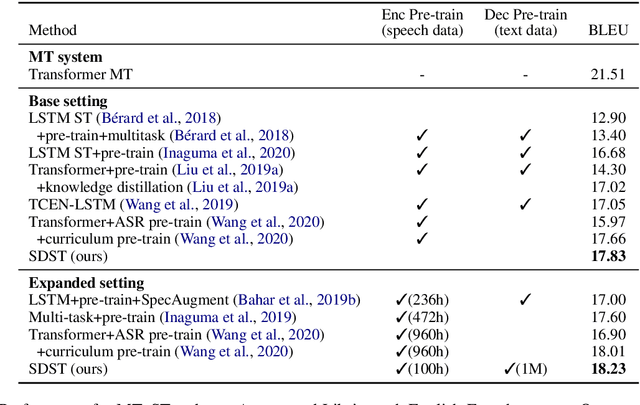
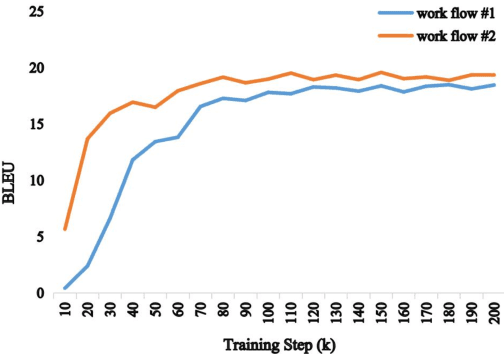
End-to-end speech-to-text translation (ST), which directly translates the source language speech to the target language text, has attracted intensive attention recently. However, the combination of speech recognition and machine translation in a single model poses a heavy burden on the direct cross-modal cross-lingual mapping. To reduce the learning difficulty, we propose SDST, an integral framework with \textbf{S}uccessive \textbf{D}ecoding for end-to-end \textbf{S}peech-to-text \textbf{T}ranslation task. This method is verified in two mainstream datasets. Experiments show that our proposed \method improves the previous state-of-the-art methods by big margins.
View paper on