 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-SLAM: A Visual Monocular SLAM Learning from Human Gaze
Paper and Code
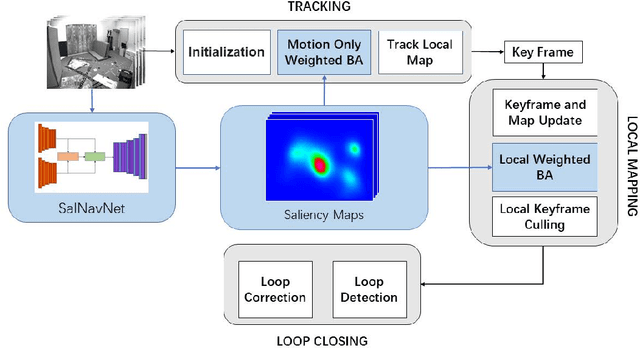
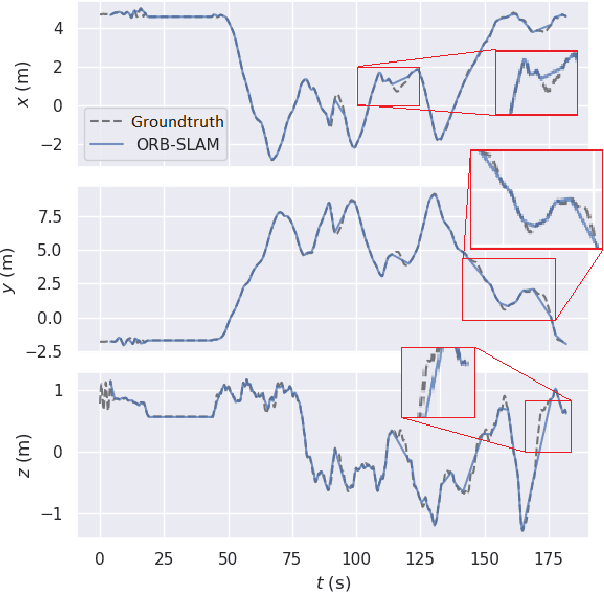
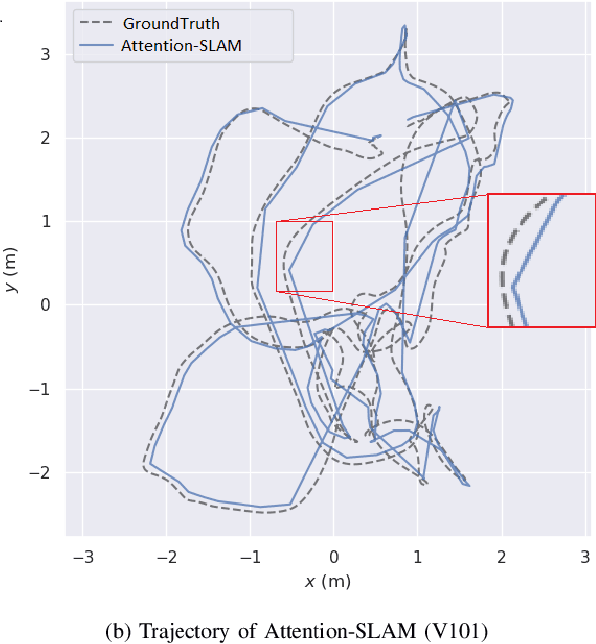
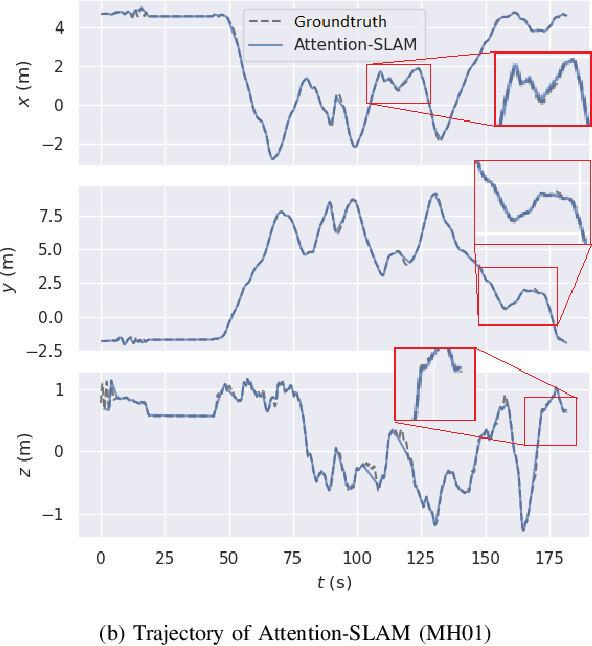
This paper proposes a novel simultaneous localization and mapping (SLAM) approach, namely Attention-SLAM, which simulates human navigation mode by combining a visual saliency model (SalNavNet) with traditional monocular visual SLAM. Most SLAM methods treat all the features extracted from the images as equal importance during the optimization process. However, the salient feature points in scenes have more significant influence during the human navigation process. Therefore, we first propose a visual saliency model called SalVavNet in which we introduce a correlation module and propose an adaptive Exponential Moving Average (EMA) module. These modules mitigate the center bias to enable the saliency maps generated by SalNavNet to pay more attention to the same salient object. Moreover, the saliency maps simulate the human behavior for the refinement of SLAM results. The feature points extracted from the salient regions have greater importance in optimization process. We add semantic saliency information to the Euroc dataset to generate an open-source saliency SLAM dataset. Comprehensive test results prove that Attention-SLAM outperforms benchmarks such as Direct Sparse Odometry (DSO), ORB-SLAM, and Salient DSO in terms of efficiency, accuracy, and robustness in most test cases.