 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster-Former: Clustering-based Sparse Transformer for Long-Range Dependency Encoding
Paper and Code
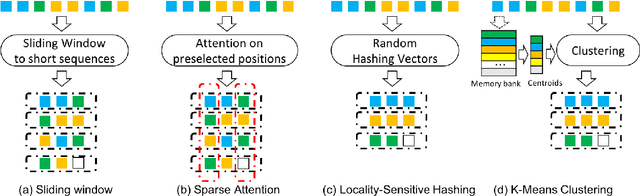
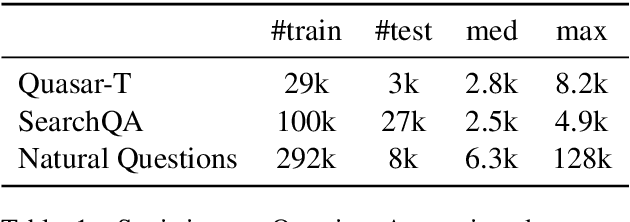
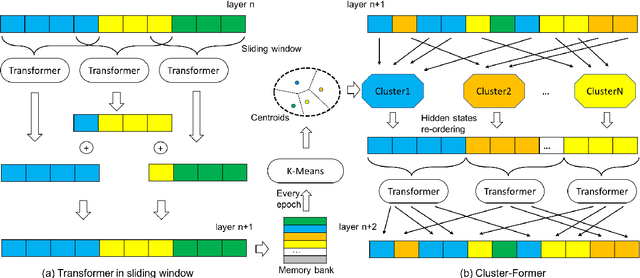
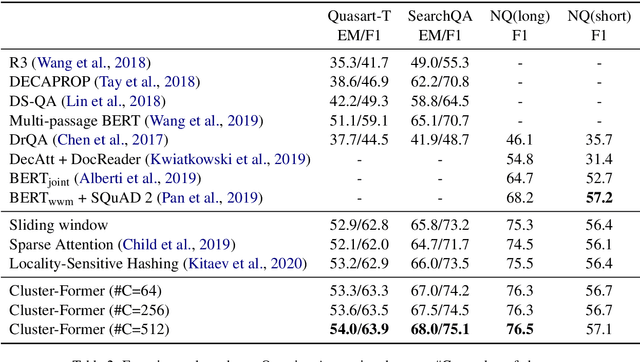
Transformer has become ubiquitous in the deep learning field. One of the key ingredients that destined its success is the self-attention mechanism, which allows fully-connected contextual encoding over input tokens. However, despite its effectiveness in modeling short sequences, self-attention suffers when handling inputs with extreme long-range dependencies, as its complexity grows quadratically with respect to the sequence length. Therefore, long sequences are often encoded by Transformer in chunks using a sliding window. In this paper, we propose Cluster-Former, a novel clustering-based sparse Transformer to perform attention across chunked sequences. Our proposed method allows information integration beyond local windows, which is especially beneficial for question answering (QA) and language modeling tasks that rely on long-range dependencies. Experiments show that Cluster-Former achieves state-of-the-art performance on several major QA benchmarks.