 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE-ViL: Knowledge Enhanced Vision-Language Representations Through Scene Graph
Paper and Code
Jun 30, 2020

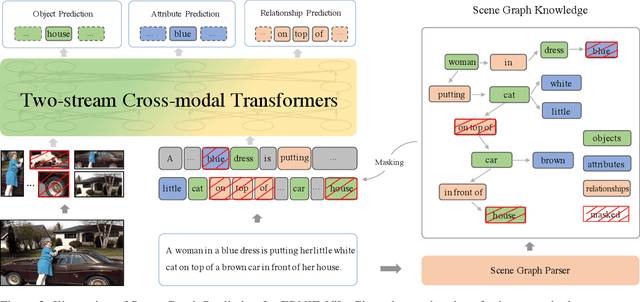
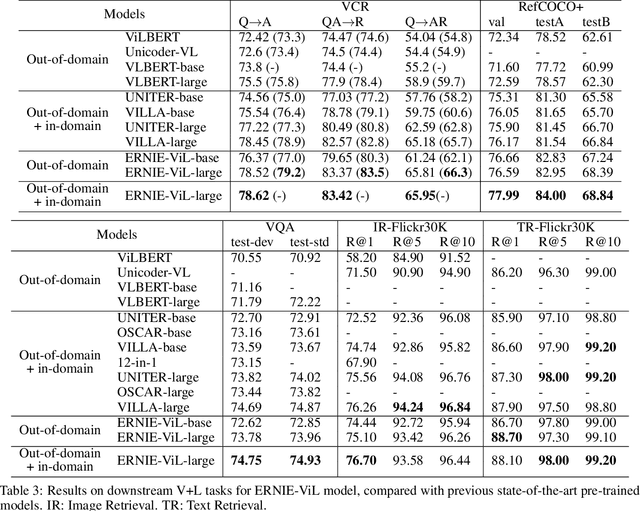
We propose a knowledge-enhanced approach, ERNIE-ViL, to learn joint representations of vision and language. ERNIE-ViL tries to construct the detailed semantic connections (objects, attributes of objects and relationships between objects in visual scenes) across vision and language, which are essential to vision-language cross-modal tasks. Incorporating knowledge from scene graphs, ERNIE-ViL constructs Scene Graph Prediction tasks, i.e., Object Prediction, Attribute Prediction and Relationship Prediction in the pre-training phase. More specifically, these prediction tasks are implemented by predicting nodes of different types in the scene graph parsed from the sentence. Thus, ERNIE-ViL can model the joint representation characterizing the alignments of the detailed semantics across vision and language. Pre-trained on two large image-text alignment datasets (Conceptual Captions and SBU), ERNIE-ViL learns better and more robust joint representations. It achieves state-of-the-art performance on 5 vision-language downstream tasks after fine-tuning ERNIE-ViL. Furthermore, it ranked the 1st place on the VCR leader-board with an absolute improvement of 3.7\%.