 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive and Generative Neural Networks for Object Functionality
Paper and Code
Jun 28, 2020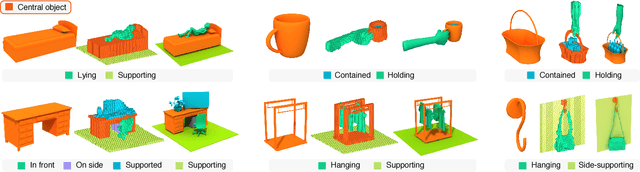

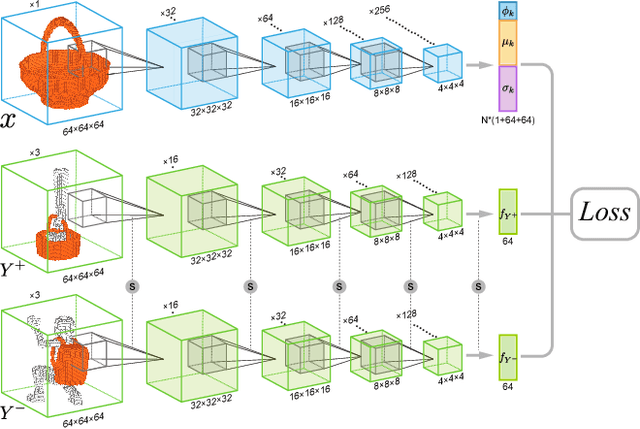
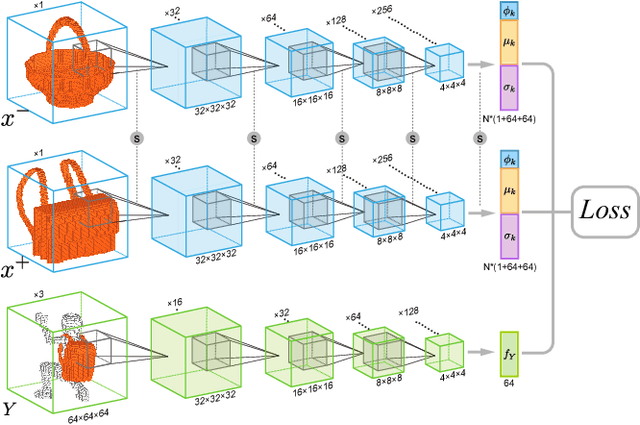
Humans can predict the functionality of an object even without any surroundings, since their knowledge and experience would allow them to "hallucinate" the interaction or usage scenarios involving the object. We develop predictive and generative deep convolutional neural networks to replicate this feat. Specifically, our work focuses on functionalities of man-made 3D objects characterized by human-object or object-object interactions. Our networks are trained on a database of scene contexts, called interaction contexts, each consisting of a central object and one or more surrounding objects, that represent object functionalities. Given a 3D object in isolation, our functional similarity network (fSIM-NET), a variation of the triplet network, is trained to predict the functionality of the object by inferring functionality-revealing interaction contexts. fSIM-NET is complemented by a generative network (iGEN-NET) and a segmentation network (iSEG-NET). iGEN-NET takes a single voxelized 3D object with a functionality label and synthesizes a voxelized surround, i.e., the interaction context which visually demonstrates the corresponding functionality. iSEG-NET further separates the interacting objects into different groups according to their interaction types.