 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRIE: End-to-End Text Reading and Information Extraction for Document Understanding
Paper and Code
May 27, 2020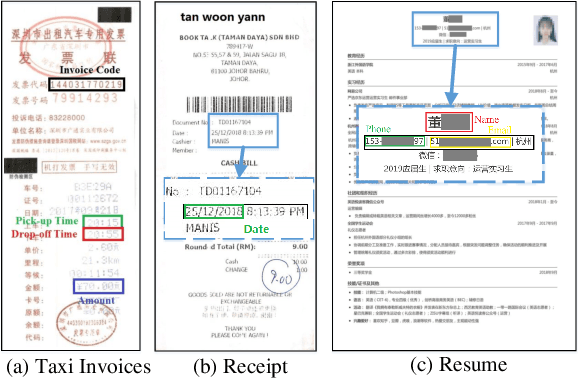
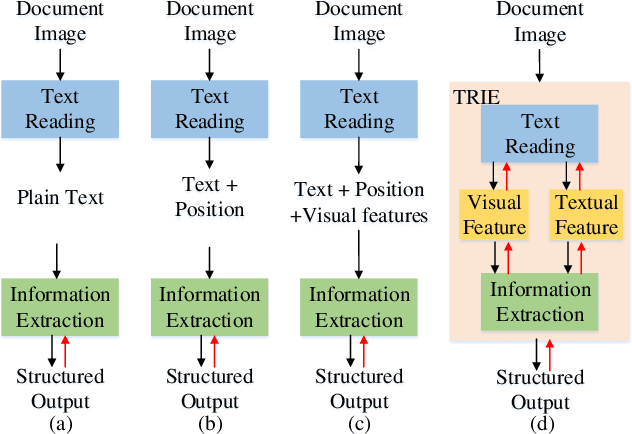
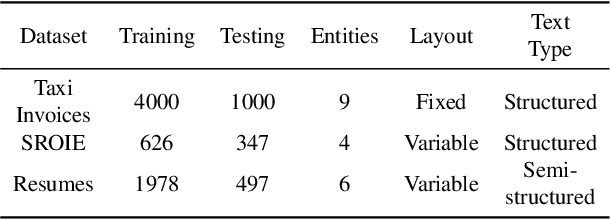
Since real-world ubiquitous documents (e.g., invoices, tickets, resumes and leaflets) contain rich information, automatic document image understanding has become a hot topic. Most existing works decouple the problem into two separate tasks, (1) text reading for detecting and recognizing texts in the images and (2) information extraction for analyzing and extracting key elements from previously extracted plain text. However, they mainly focus on improving information extraction task, while neglecting the fact that text reading and information extraction are mutually correlated. In this paper, we propose a unified end-to-end text reading and information extraction network, where the two tasks can reinforce each other. Specifically, the multimodal visual and textual features of text reading are fused for information extraction and in turn, the semantics in information extraction contribute to the optimization of text reading. On three real-world datasets with diverse document images (from fixed layout to variable layout, from structured text to semi-structured text), our proposed method significantly outperforms the state-of-the-art methods in both efficiency and accuracy.