 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartExchange: Trading Higher-cost Memory Storage/Access for Lower-cost Computation
Paper and Code
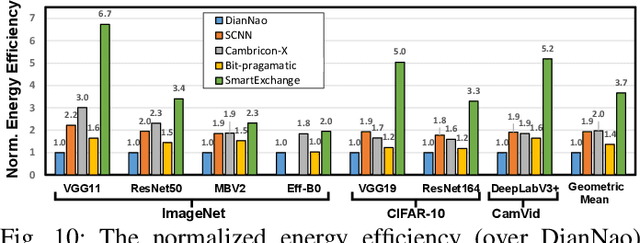
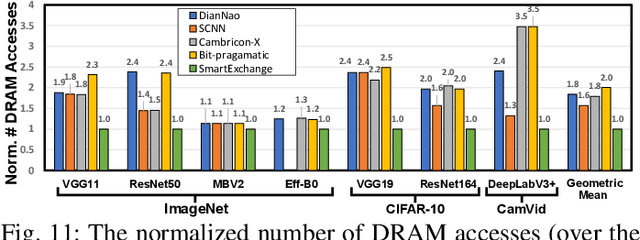
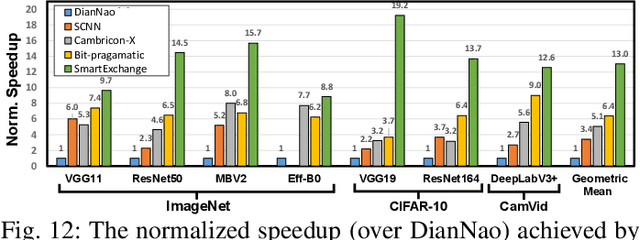
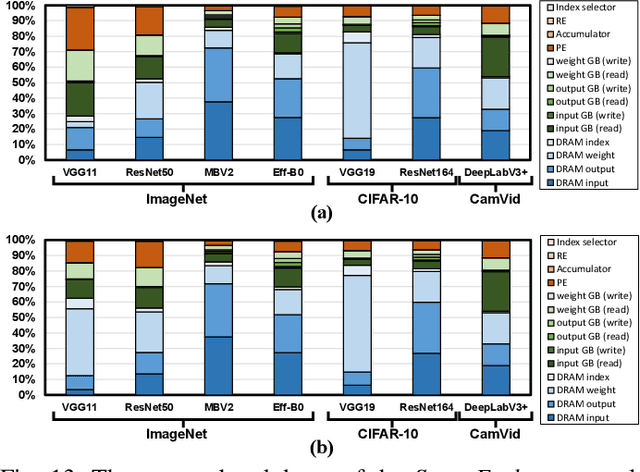
We present SmartExchange, an algorithm-hardware co-design framework to trade higher-cost memory storage/access for lower-cost computation, for energy-efficient inference of deep neural networks (DNNs). We develop a novel algorithm to enforce a specially favorable DNN weight structure, where each layerwise weight matrix can be stored as the product of a small basis matrix and a large sparse coefficient matrix whose non-zero elements are all power-of-2. To our best knowledge, this algorithm is the first formulation that integrates three mainstream model compression ideas: sparsification or pruning, decomposition, and quantization, into one unified framework. The resulting sparse and readily-quantized DNN thus enjoys greatly reduced energy consumption in data movement as well as weight storage. On top of that, we further design a dedicated accelerator to fully utilize the SmartExchange-enforced weights to improve both energy efficiency and latency performance. Extensive experiments show that 1) on the algorithm level, SmartExchange outperforms state-of-the-art compression techniques, including merely sparsification or pruning, decomposition, and quantization, in various ablation studies based on nine DNN models and four datasets; and 2) on the hardware level, the proposed SmartExchange based accelerator can improve the energy efficiency by up to 6.7$\times$ and the speedup by up to 19.2$\times$ over four state-of-the-art DNN accelerators, when benchmarked on seven DNN models (including four standard DNNs, two compact DNN models, and one segmentation model) and three datasets.