 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDGD: Densifying the Knowledge of Neural Networks with Filter Grafting and Knowledge Distillation
Paper and Code
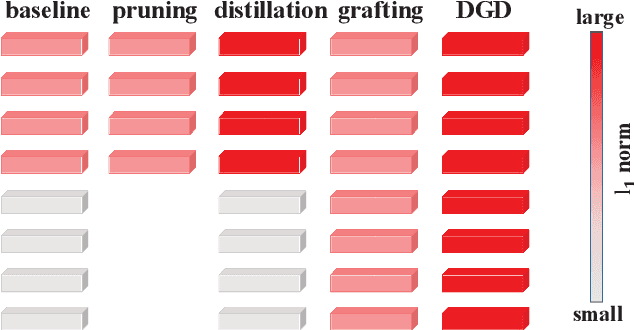
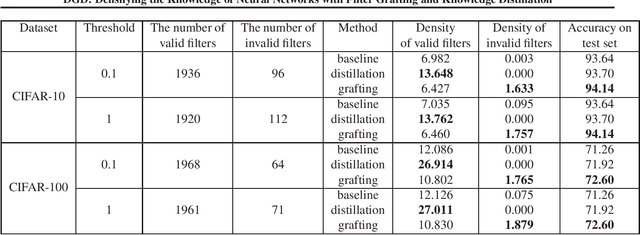
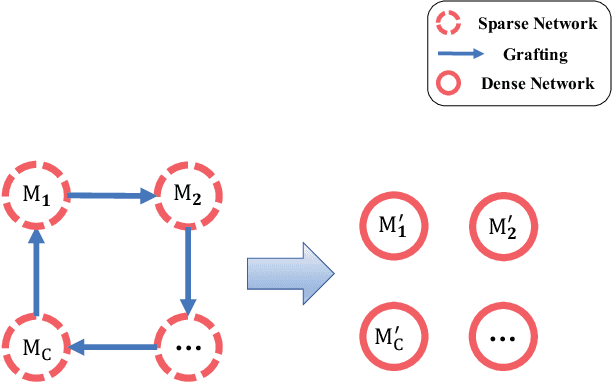
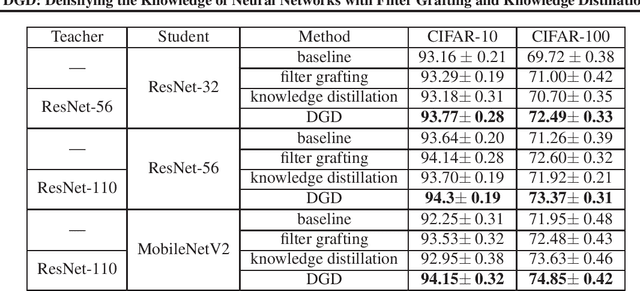
With a fixed model structure, knowledge distillation and filter grafting are two effective ways to boost single model accuracy. However, the working mechanism and the differences between distillation and grafting have not been fully unveiled. In this paper, we evaluate the effect of distillation and grafting in the filter level, and find that the impacts of the two techniques are surprisingly complementary: distillation mostly enhances the knowledge of valid filters while grafting mostly reactivates invalid filters. This observation guides us to design a unified training framework called DGD, where distillation and grafting are naturally combined to increase the knowledge density inside the filters given a fixed model structure. Through extensive experiments, we show that the knowledge densified network in DGD shares both advantages of distillation and grafting, lifting the model accuracy to a higher level.