 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Action Maps for Mobile Manipulation
Paper and Code
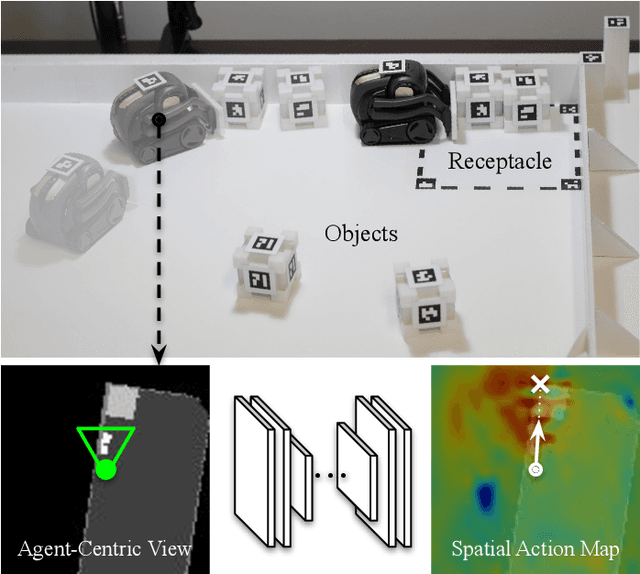


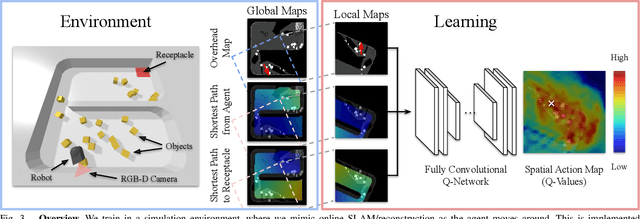
This paper proposes a new action representation for learning to perform complex mobile manipulation tasks. In a typical deep Q-learning setup, a convolutional neural network (ConvNet) is trained to map from an image representing the current state (e.g., a birds-eye view of a SLAM reconstruction of the scene) to predicted Q-values for a small set of steering command actions (step forward, turn right, turn left, etc.). Instead, we propose an action representation in the same domain as the state: "spatial action maps." In our proposal, the set of possible actions is represented by pixels of an image, where each pixel represents a trajectory to the corresponding scene location along a shortest path through obstacles of the partially reconstructed scene. A significant advantage of this approach is that the spatial position of each state-action value prediction represents a local milestone (local end-point) for the agent's policy, which may be easily recognizable in local visual patterns of the state image. A second advantage is that atomic actions can perform long-range plans (follow the shortest path to a point on the other side of the scene), and thus it is simpler to learn complex behaviors with a deep Q-network. A third advantage is that we can use a fully convolutional network (FCN) with skip connections to learn the mapping from state images to pixel-aligned action images efficiently. During experiments with a robot that learns to push objects to a goal location, we find that policies learned with this proposed action representation achieve significantly better performance than traditional alternatives.