 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolweni: A Challenge Multiparty Dialogues-based Machine Reading Comprehension Dataset with Discourse Structure
Paper and Code


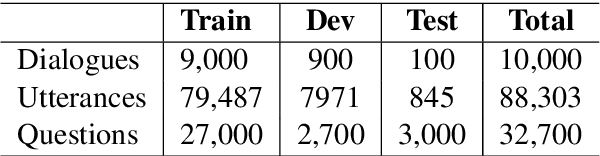
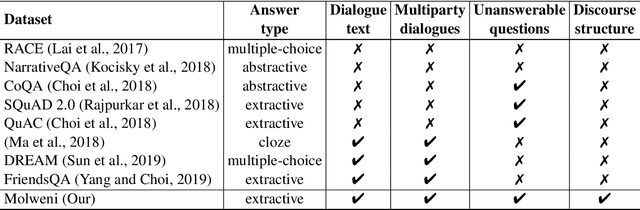
We present the Molweni dataset, a machine reading comprehension (MRC) dataset built over multiparty dialogues. Molweni's source samples from the Ubuntu Chat Corpus, including 10,000 dialogues comprising 88,303 utterances. We annotate 32,700 questions on this corpus, including both answerable and unanswerable questions. Molweni also uniquely contributes discourse dependency annotations for its multiparty dialogues, contributing large-scale (78,246 annotated discourse relations) data to bear on the task of multiparty dialogue understanding. Our experiments show that Molweni is a challenging dataset for current MRC models; BERT-wwm, a current, strong SQuAD 2.0 performer, achieves only 67.7% F1 on Molweni's questions, a 20+% significant drop as compared against its SQuAD 2.0 performance.