 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Privacy-Preserving DNN Pruning and Mobile Acceleration Framework
Paper and Code
Mar 13, 2020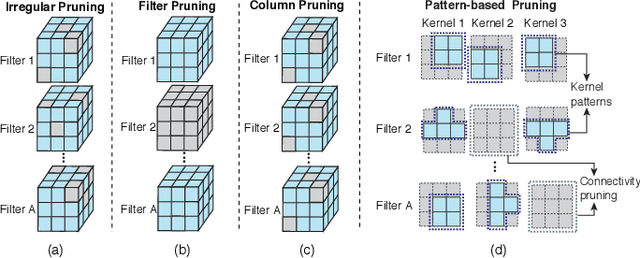
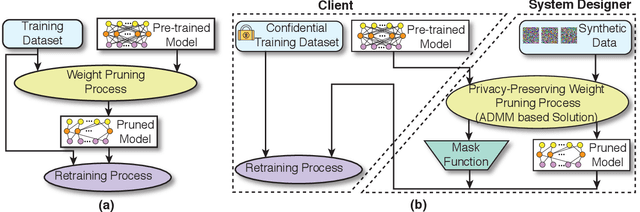
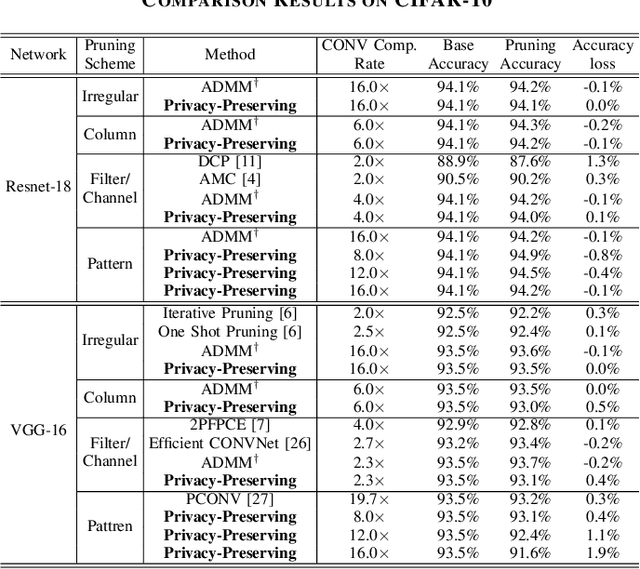
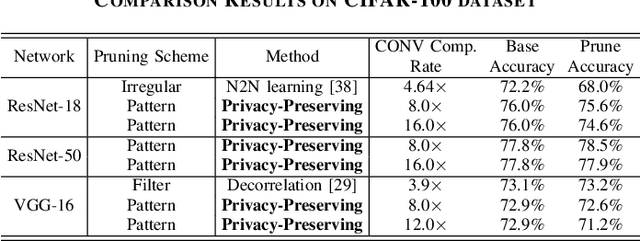
To facilitate the deployment of deep neural networks (DNNs) on resource-constrained computing systems, DNN model compression methods have been proposed. However, previous methods mainly focus on reducing the model size and/or improving hardware performance, without considering the data privacy requirement. This paper proposes a privacy-preserving model compression framework that formulates a privacy-preserving DNN weight pruning problem and develops an ADMM based solution to support different weight pruning schemes. We consider the case that the system designer will perform weight pruning on a pre-trained model provided by the client, whereas the client cannot share her confidential training dataset. To mitigate the non-availability of the training dataset, the system designer distills the knowledge of a pre-trained model into a pruned model using only randomly generated synthetic data. Then the client's effort is simply reduced to performing the retraining process using her confidential training dataset, which is similar as the DNN training process with the help of the mask function from the system designer. Both algorithmic and hardware experiments validate the effectiveness of the proposed framework.