 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUOD: A Scalable Unsupervised Outlier Detection Framework
Paper and Code
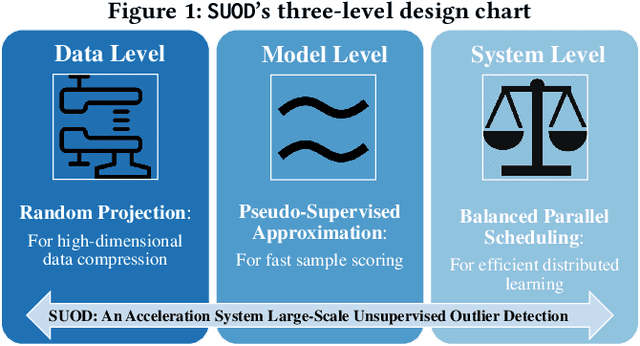
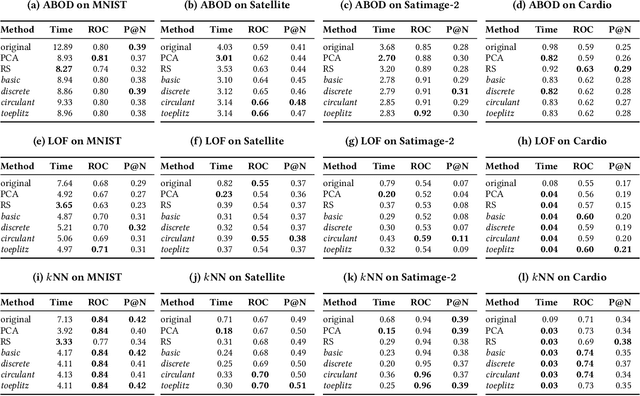
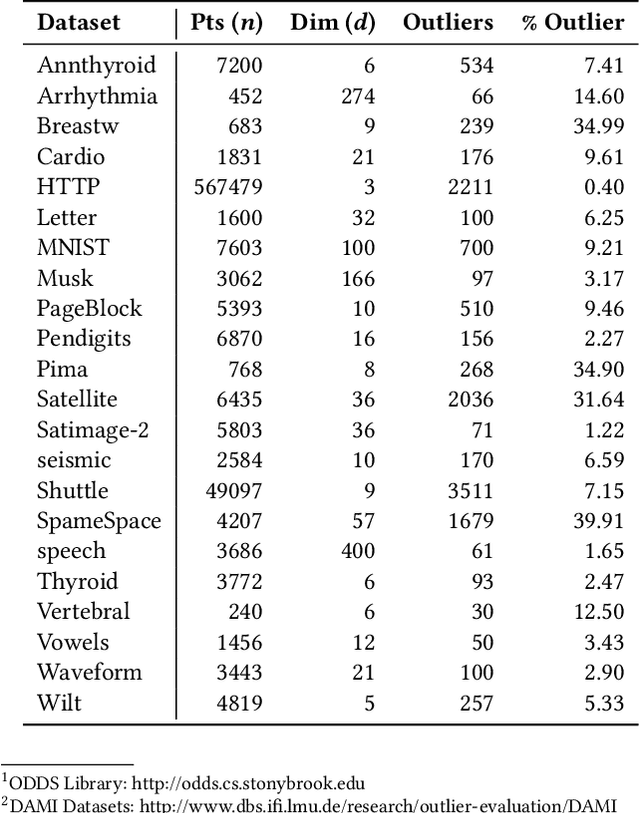
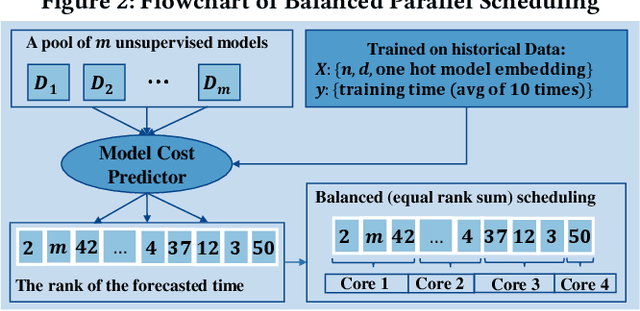
Outlier detection is a key data mining task for identifying abnormal objects from massive data. Due to the high expense of acquiring ground truth, practitioners lean towards building a large number of unsupervised models for further combination and analysis, rather than relying on a single model out of reliability consideration. However, this poses scalability challenge to high-dimensional, large datasets. In this study, we propose a three-module framework called SUOD to address the challenge. It can accelerate outlier model building and scoring when a large number of base models are used. It focuses on three complementary levels to speed up the process while controlling prediction performance degradation at the same time. At the data level, its Random Projection module projects high-dimensional data onto diversified low-dimensional subspaces while preserving the pairwise distance relationship. At the model level, SUOD's Pseudo-supervised Approximation module can approximate and replace fitted unsupervised models by low-cost supervised regressors, leading to fast offline scoring on new-coming samples with better interpretability. At the system level, Balanced Parallel Scheduling module mitigates the workload imbalance within distributed systems, which is helpful for heterogeneous outlier ensembles. As the three modules are independent with different focuses, they have great flexibility to "mix and match". The framework is also designed with extensibility in mind. One may customize each module based on specific use cases, and the framework may be generalized to other learning tasks as well. Extensive experiments on more than 20 benchmark datasets demonstrate SUOD's effectiveness. In addition, a real-world deployment system on fraudulent claim analysis by IQVIA is also discussed. The full framework, documentation, and examples are openly shared at https://github.com/yzhao062/SUOD.