 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLK-REW: A Unified Block-based DNN Pruning Framework using Reweighted Regularization Method
Paper and Code
Feb 22, 2020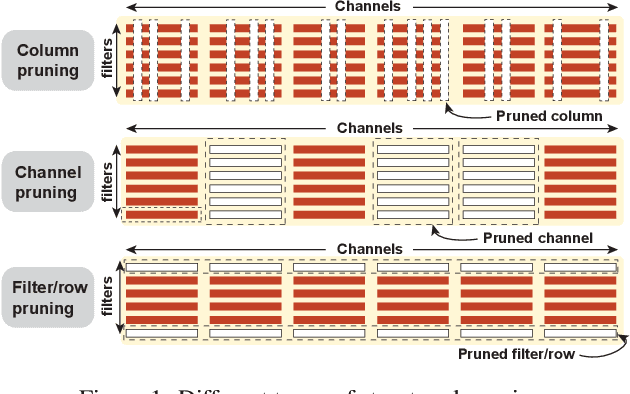
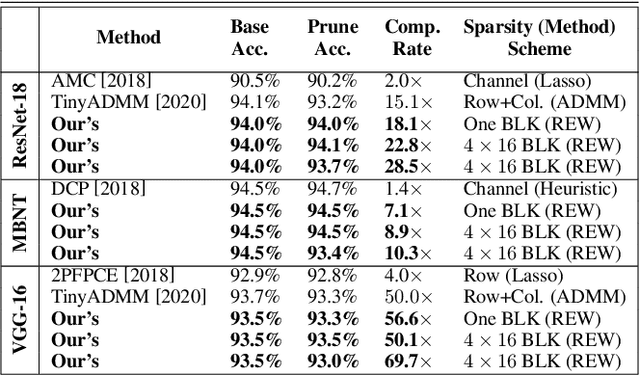
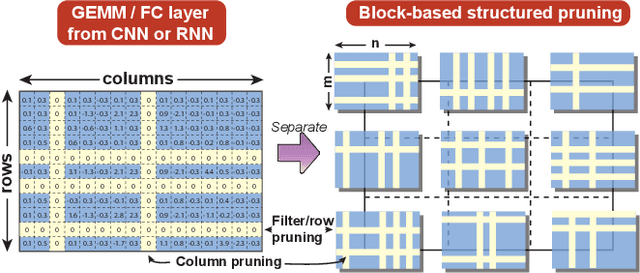
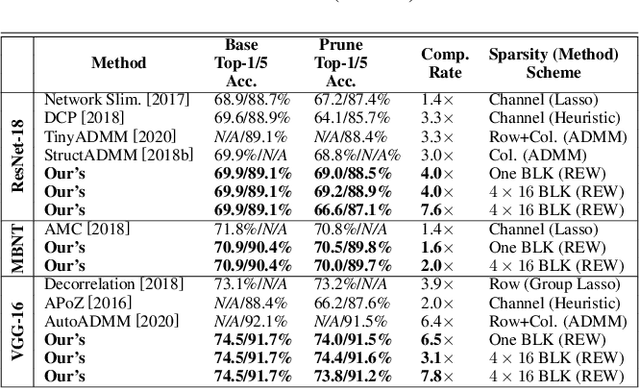
Accelerating DNN execution on various resource-limited computing platforms has been a long-standing problem. Prior works utilize l1-based group lasso or dynamic regularization such as ADMM to perform structured pruning on DNN models to leverage the parallel computing architectures. However, both of the pruning dimensions and pruning methods lack universality, which leads to degraded performance and limited applicability. To solve the problem, we propose a new block-based pruning framework that comprises a general and flexible structured pruning dimension as well as a powerful and efficient reweighted regularization method. Our framework is universal, which can be applied to both CNNs and RNNs, implying complete support for the two major kinds of computation-intensive layers (i.e., CONV and FC layers). To complete all aspects of the pruning-for-acceleration task, we also integrate compiler-based code optimization into our framework that can perform DNN inference in a real-time manner. To the best of our knowledge, it is the first time that the weight pruning framework achieves universal coverage for both CNNs and RNNs with real-time mobile acceleration and no accuracy compromise.