 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantization Networks
Paper and Code
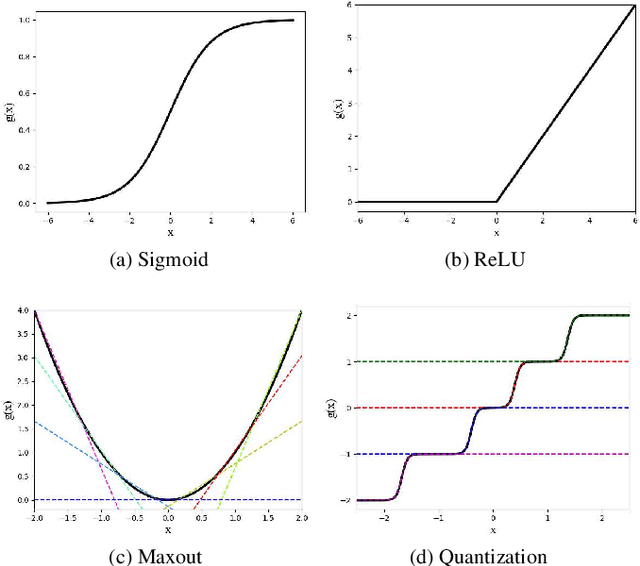
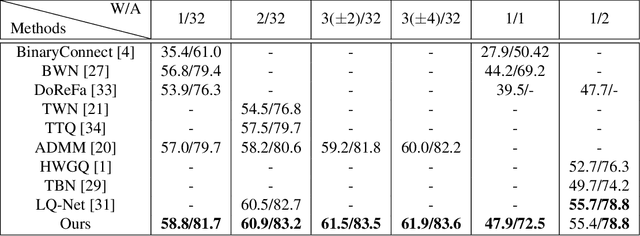

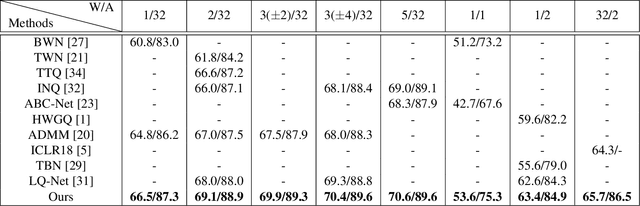
Although deep neural networks are highly effective, their high computational and memory costs severely challenge their applications on portable devices. As a consequence, low-bit quantization, which converts a full-precision neural network into a low-bitwidth integer version, has been an active and promising research topic. Existing methods formulate the low-bit quantization of networks as an approximation or optimization problem. Approximation-based methods confront the gradient mismatch problem, while optimization-based methods are only suitable for quantizing weights and could introduce high computational cost in the training stage. In this paper, we propose a novel perspective of interpreting and implementing neural network quantization by formulating low-bit quantization as a differentiable non-linear function (termed quantization function). The proposed quantization function can be learned in a lossless and end-to-end manner and works for any weights and activations of neural networks in a simple and uniform way. Extensive experiments on image classification and object detection tasks show that our quantization networks outperform the state-of-the-art methods. We believe that the proposed method will shed new insights on the interpretation of neural network quantization. Our code is available at https://github.com/aliyun/alibabacloud-quantization-networks.