 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Imitation Learning from Demonstrations for Legged Robot Visual Navigation
Paper and Code
Sep 27, 2019
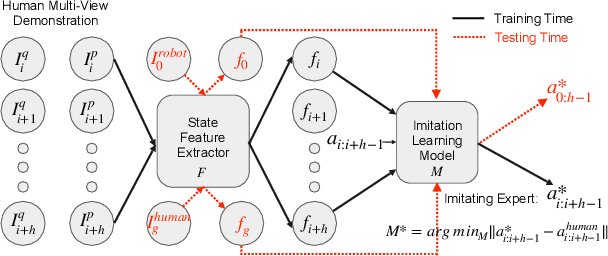
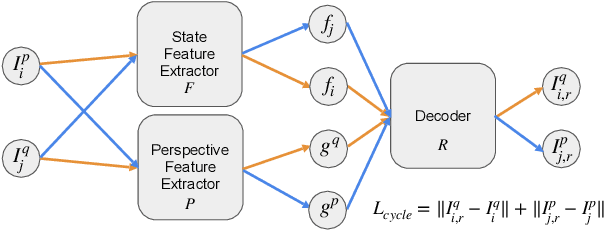
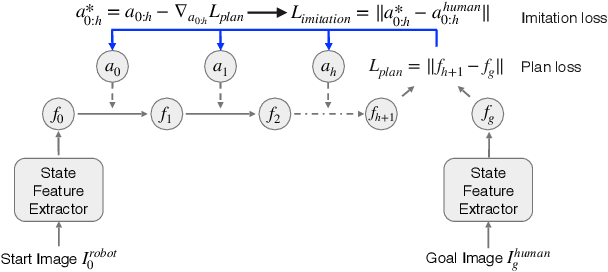
Imitation learning is a popular approach for training effective visual navigation policies. However, for legged robots collecting expert demonstrations is challenging as these robotic systems can be hard to control, move slowly, and cannot operate continuously for long periods of time. In this work, we propose a zero-shot imitation learning framework for training a visual navigation policy on a legged robot from only human demonstration (third-person perspective), allowing for high-quality navigation and cost-effective data collection. However, imitation learning from third-person perspective demonstrations raises unique challenges. First, these human demonstrations are captured from different camera perspectives, which we address via a feature disentanglement network~(FDN) that extracts perspective-agnostic state features. Second, as potential actions vary between systems, we reconstruct missing action labels by either building an inverse model of the robot's dynamics in the feature space and applying it to the demonstrations or developing an efficient Graphic User Interface (GUI) to label human demonstrations. To train a visual navigation policy we use a model-based imitation learning approach with the perspective-agnostic FDN and action-labeled demonstrations. We show that our framework can learn an effective policy for a legged robot, Laikago, from expert demonstrations in both simulated and real-world environments. Our approach is zero-shot as the robot never tries to navigate a given navigation path in the testing environment before the testing phase. We also justify our framework by performing an ablation study and comparing it with baselines.