 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChinese Street View Text: Large-scale Chinese Text Reading with Partially Supervised Learning
Paper and Code

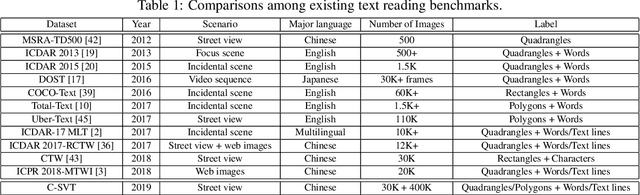

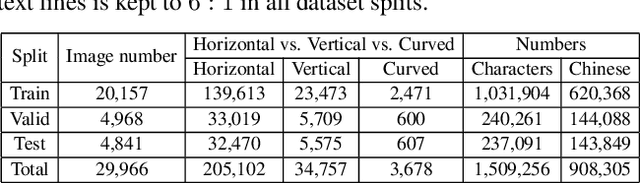
Most existing text reading benchmarks make it difficult to evaluate the performance of more advanced deep learning models in large vocabularies due to the limited amount of training data. To address this issue, we introduce a new large-scale text reading benchmark dataset named Chinese Street View Text (C-SVT) with 430,000 street view images, which is at least 14 times as large as the existing Chinese text reading benchmarks. To recognize Chinese text in the wild while keeping large-scale datasets labeling cost-effective, we propose to annotate one part of the CSVT dataset (30,000 images) in locations and text labels as full annotations and add 400,000 more images, where only the corresponding text-of-interest in the regions is given as weak annotations. To exploit the rich information from the weakly annotated data, we design a text reading network in a partially supervised learning framework, which enables to localize and recognize text, learn from fully and weakly annotated data simultaneously. To localize the best matched text proposals from weakly labeled images, we propose an online proposal matching module incorporated in the whole model, spotting the keyword regions by sharing parameters for end-to-end training. Compared with fully supervised training algorithms, this model can improve the end-to-end recognition performance remarkably by 4.03% in F-score at the same labeling cost. The proposed model can also achieve state-of-the-art results on the ICDAR 2017-RCTW dataset, which demonstrates the effectiveness of the proposed partially supervised learning framework.