 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditing Text in the Wild
Paper and Code

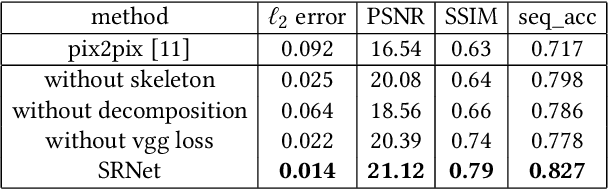
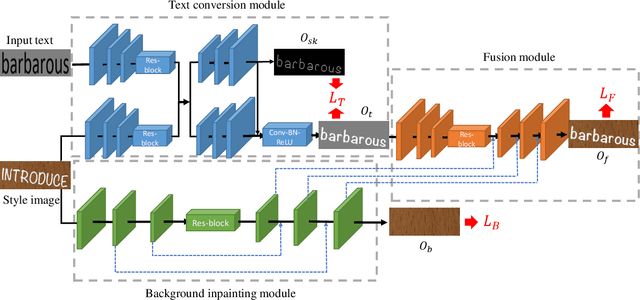

In this paper, we are interested in editing text in natural images, which aims to replace or modify a word in the source image with another one while maintaining its realistic look. This task is challenging, as the styles of both background and text need to be preserved so that the edited image is visually indistinguishable from the source image. Specifically, we propose an end-to-end trainable style retention network (SRNet) that consists of three modules: text conversion module, background inpainting module and fusion module. The text conversion module changes the text content of the source image into the target text while keeping the original text style. The background inpainting module erases the original text, and fills the text region with appropriate texture. The fusion module combines the information from the two former modules, and generates the edited text images. To our knowledge, this work is the first attempt to edit text in natural images at the word level. Both visual effects and quantitative results on synthetic and real-world dataset (ICDAR 2013) fully confirm the importance and necessity of modular decomposition. We also conduct extensive experiments to validate the usefulness of our method in various real-world applications such as text image synthesis, augmented reality (AR) translation, information hiding, etc.