 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive DNN Compression: A Key to Achieve Ultra-High Weight Pruning and Quantization Rates using ADMM
Paper and Code
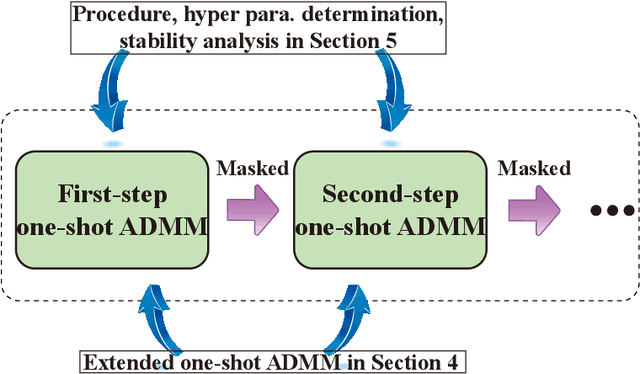
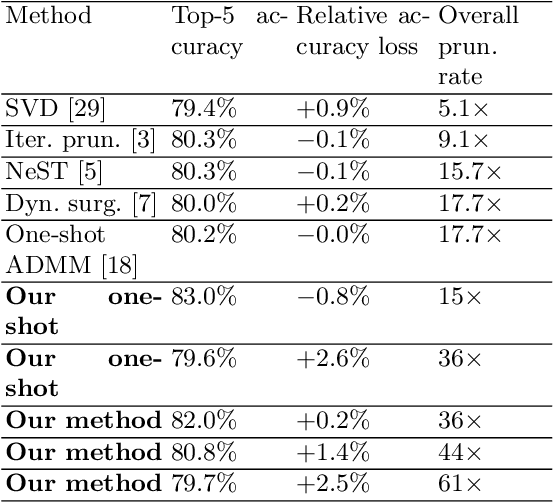
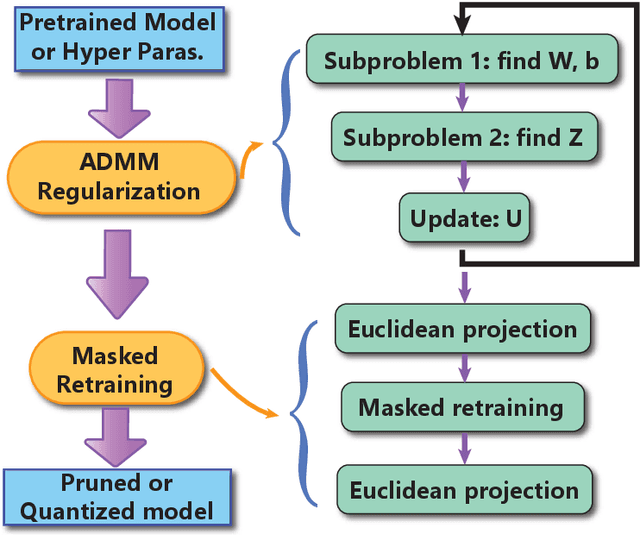
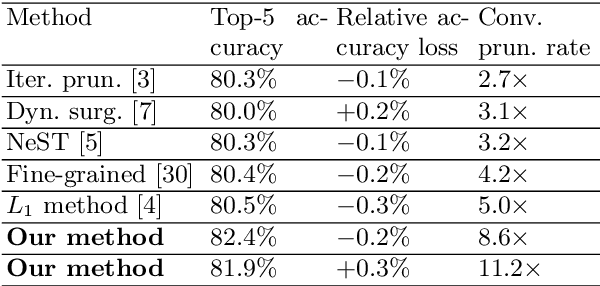
Weight pruning and weight quantization are two important categories of DNN model compression. Prior work on these techniques are mainly based on heuristics. A recent work developed a systematic frame-work of DNN weight pruning using the advanced optimization technique ADMM (Alternating Direction Methods of Multipliers), achieving one of state-of-art in weight pruning results. In this work, we first extend such one-shot ADMM-based framework to guarantee solution feasibility and provide fast convergence rate, and generalize to weight quantization as well. We have further developed a multi-step, progressive DNN weight pruning and quantization framework, with dual benefits of (i) achieving further weight pruning/quantization thanks to the special property of ADMM regularization, and (ii) reducing the search space within each step. Extensive experimental results demonstrate the superior performance compared with prior work. Some highlights: (i) we achieve 246x,36x, and 8x weight pruning on LeNet-5, AlexNet, and ResNet-50 models, respectively, with (almost) zero accuracy loss; (ii) even a significant 61x weight pruning in AlexNet (ImageNet) results in only minor degradation in actual accuracy compared with prior work; (iii) we are among the first to derive notable weight pruning results for ResNet and MobileNet models; (iv) we derive the first lossless, fully binarized (for all layers) LeNet-5 for MNIST and VGG-16 for CIFAR-10; and (v) we derive the first fully binarized (for all layers) ResNet for ImageNet with reasonable accuracy loss.