 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexar: A Modularized, Versatile, and Extensible Toolkit for Text Generation
Paper and Code
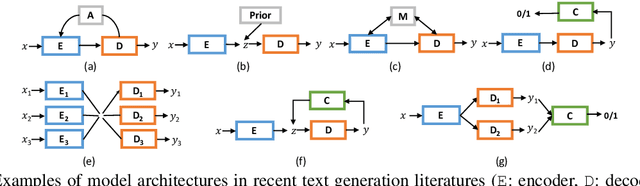
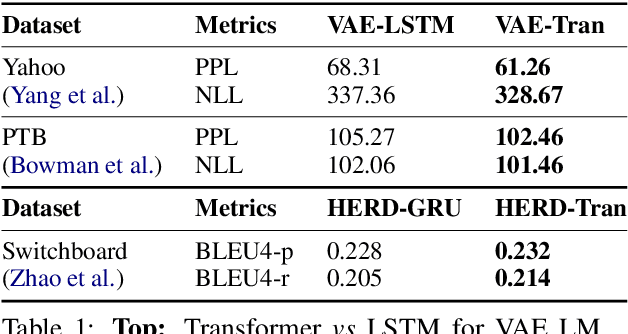
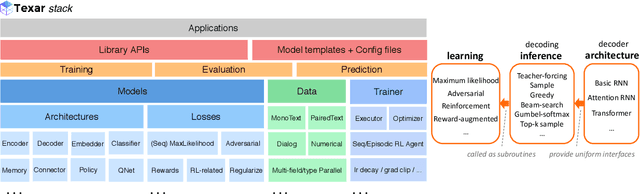

We introduce Texar, an open-source toolkit aiming to support the broad set of text generation tasks that transforms any inputs into natural language, such as machine translation, summarization, dialog, content manipulation, and so forth. With the design goals of modularity, versatility, and extensibility in mind, Texar extracts common patterns underlying the diverse tasks and methodologies, creates a library of highly reusable modules and functionalities, and allows arbitrary model architectures and algorithmic paradigms. In Texar, model architecture, losses, and learning processes are fully decomposed. Modules at high concept level can be freely assembled or plugged in/swapped out. These features make Texar particularly suitable for researchers and practitioners to do fast prototyping and experimentation, as well as foster technique sharing across different text generation tasks. We provide case studies to demonstrate the use and advantage of the toolkit. Texar is released under Apache license 2.0 at https://github.com/asyml/texar.