 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Than a Feeling: Learning to Grasp and Regrasp using Vision and Touch
Paper and Code
Jul 26, 2018

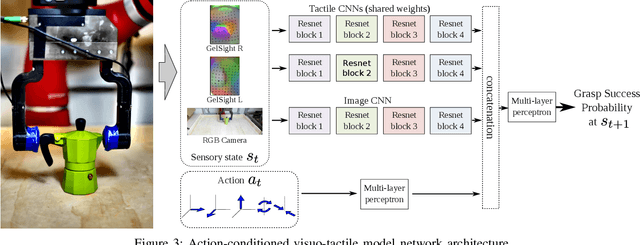

For humans, the process of grasping an object relies heavily on rich tactile feedback. Most recent robotic grasping work, however, has been based only on visual input, and thus cannot easily benefit from feedback after initiating contact. In this paper, we investigate how a robot can learn to use tactile information to iteratively and efficiently adjust its grasp. To this end, we propose an end-to-end action-conditional model that learns regrasping policies from raw visuo-tactile data. This model -- a deep, multimodal convolutional network -- predicts the outcome of a candidate grasp adjustment, and then executes a grasp by iteratively selecting the most promising actions. Our approach requires neither calibration of the tactile sensors, nor any analytical modeling of contact forces, thus reducing the engineering effort required to obtain efficient grasping policies. We train our model with data from about 6,450 grasping trials on a two-finger gripper equipped with GelSight high-resolution tactile sensors on each finger. Across extensive experiments, our approach outperforms a variety of baselines at (i) estimating grasp adjustment outcomes, (ii) selecting efficient grasp adjustments for quick grasping, and (iii) reducing the amount of force applied at the fingers, while maintaining competitive performance. Finally, we study the choices made by our model and show that it has successfully acquired useful and interpretable grasping behaviors.