 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Sequence Robot Behaviors for Visual Navigation
Paper and Code
Mar 26, 2018

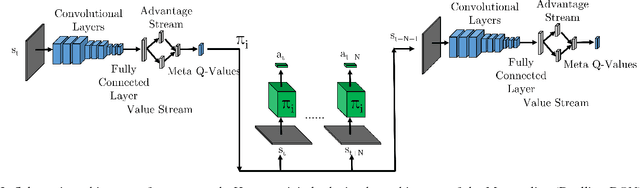

Recent literature in the robotics community has focused on learning robot behaviors that abstract out lower-level details of robot control. To fully leverage the efficacy of such behaviors, it is necessary to select and sequence them to achieve a given task. In this paper, we present an approach to both learn and sequence robot behaviors, applied to the problem of visual navigation of mobile robots. We construct a layered representation of control policies composed of low- level behaviors and a meta-level policy. The low-level behaviors enable the robot to locomote in a particular environment while avoiding obstacles, and the meta-level policy actively selects the low-level behavior most appropriate for the current situation based purely on visual feedback. We demonstrate the effectiveness of our method on three simulated robot navigation tasks: a legged hexapod robot which must successfully traverse varying terrain, a wheeled robot which must navigate a maze-like course while avoiding obstacles, and finally a wheeled robot navigating in the presence of dynamic obstacles. We show that by learning control policies in a layered manner, we gain the ability to successfully traverse new compound environments composed of distinct sub-environments, and outperform both the low-level behaviors in their respective sub-environments, as well as a hand-crafted selection of low-level policies on these compound environments.