 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebFAQ 2.0: A Multilingual QA Dataset with Mined Hard Negatives for Dense Retrieval
Feb 19, 2026We introduce WebFAQ 2.0, a new version of the WebFAQ dataset, containing 198 million FAQ-based natural question-answer pairs across 108 languages. Compared to the previous version, it significantly expands multilingual coverage and the number of bilingual aligned QA pairs to over 14.3M, making it the largest FAQ-based resource. Unlike the original release, WebFAQ 2.0 uses a novel data collection strategy that directly crawls and extracts relevant web content, resulting in a substantially more diverse and multilingual dataset with richer context through page titles and descriptions. In response to community feedback, we also release a hard negatives dataset for training dense retrievers, with 1.25M queries across 20 languages. These hard negatives were mined using a two-stage retrieval pipeline and include cross-encoder scores for 200 negatives per query. We further show how this resource enables two primary fine-tuning strategies for dense retrievers: Contrastive Learning with MultipleNegativesRanking loss, and Knowledge Distillation with MarginMSE loss. WebFAQ 2.0 is not a static resource but part of a long-term effort. Since late 2025, structured FAQs are being regularly released through the Open Web Index, enabling continuous expansion and refinement. We publish the datasets and training scripts to facilitate further research in multilingual and cross-lingual IR. The dataset itself and all related resources are publicly available on GitHub and HuggingFace.
Learning to Sequence Robot Behaviors for Visual Navigation
Mar 26, 2018

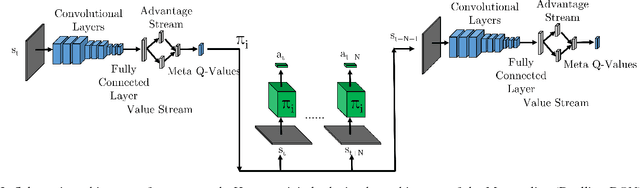

Recent literature in the robotics community has focused on learning robot behaviors that abstract out lower-level details of robot control. To fully leverage the efficacy of such behaviors, it is necessary to select and sequence them to achieve a given task. In this paper, we present an approach to both learn and sequence robot behaviors, applied to the problem of visual navigation of mobile robots. We construct a layered representation of control policies composed of low- level behaviors and a meta-level policy. The low-level behaviors enable the robot to locomote in a particular environment while avoiding obstacles, and the meta-level policy actively selects the low-level behavior most appropriate for the current situation based purely on visual feedback. We demonstrate the effectiveness of our method on three simulated robot navigation tasks: a legged hexapod robot which must successfully traverse varying terrain, a wheeled robot which must navigate a maze-like course while avoiding obstacles, and finally a wheeled robot navigating in the presence of dynamic obstacles. We show that by learning control policies in a layered manner, we gain the ability to successfully traverse new compound environments composed of distinct sub-environments, and outperform both the low-level behaviors in their respective sub-environments, as well as a hand-crafted selection of low-level policies on these compound environments.