 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatching-CNN Meets KNN: Quasi-Parametric Human Parsing
Paper and Code
Apr 06, 2015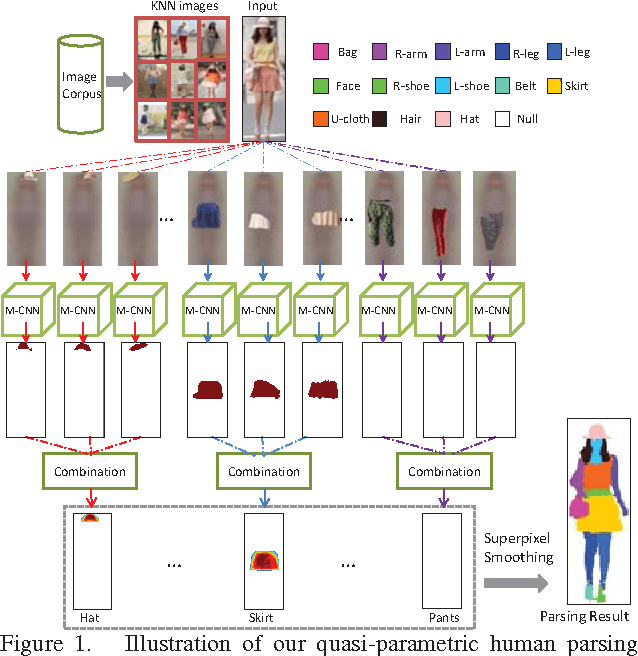

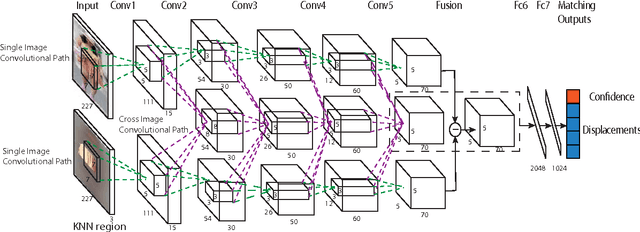
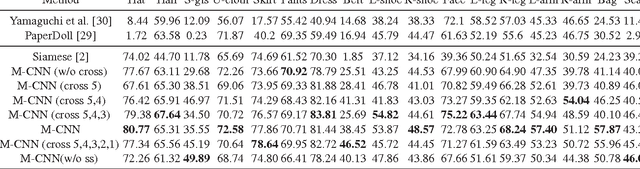
Both parametric and non-parametric approaches have demonstrated encouraging performances in the human parsing task, namely segmenting a human image into several semantic regions (e.g., hat, bag, left arm, face). In this work, we aim to develop a new solution with the advantages of both methodologies, namely supervision from annotated data and the flexibility to use newly annotated (possibly uncommon) images, and present a quasi-parametric human parsing model. Under the classic K Nearest Neighbor (KNN)-based nonparametric framework, the parametric Matching Convolutional Neural Network (M-CNN) is proposed to predict the matching confidence and displacements of the best matched region in the testing image for a particular semantic region in one KNN image. Given a testing image, we first retrieve its KNN images from the annotated/manually-parsed human image corpus. Then each semantic region in each KNN image is matched with confidence to the testing image using M-CNN, and the matched regions from all KNN images are further fused, followed by a superpixel smoothing procedure to obtain the ultimate human parsing result. The M-CNN differs from the classic CNN in that the tailored cross image matching filters are introduced to characterize the matching between the testing image and the semantic region of a KNN image. The cross image matching filters are defined at different convolutional layers, each aiming to capture a particular range of displacements. Comprehensive evaluations over a large dataset with 7,700 annotated human images well demonstrate the significant performance gain from the quasi-parametric model over the state-of-the-arts, for the human parsing task.