 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2010 Task 8: Multi-Way Classification of Semantic Relations Between Pairs of Nominals
Nov 23, 2019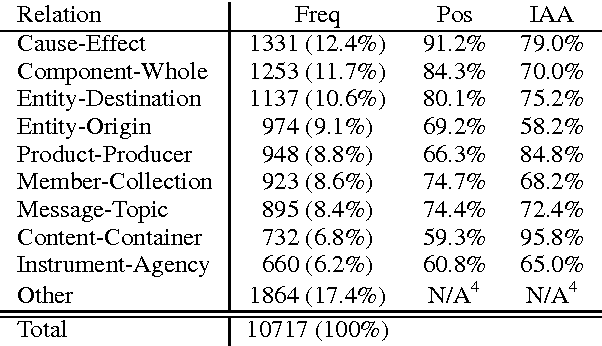
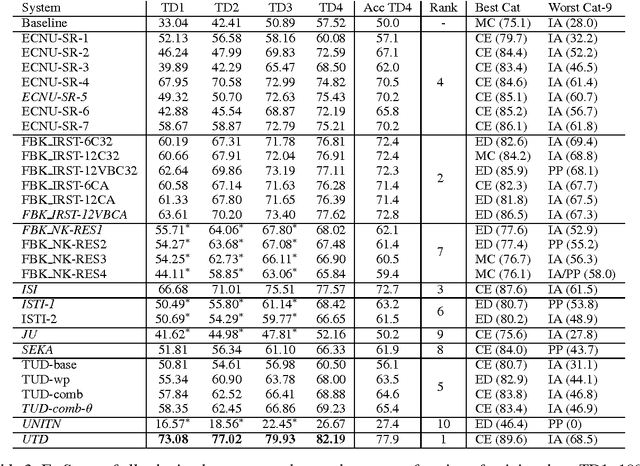
In response to the continuing research interest in computational semantic analysis, we have proposed a new task for SemEval-2010: multi-way classification of mutually exclusive semantic relations between pairs of nominals. The task is designed to compare different approaches to the problem and to provide a standard testbed for future research. In this paper, we define the task, describe the creation of the datasets, and discuss the results of the participating 28 systems submitted by 10 teams.
* semantic relations, nominals
SemEval-2013 Task 4: Free Paraphrases of Noun Compounds
Nov 23, 2019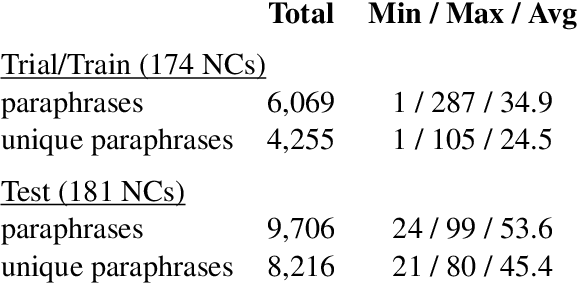
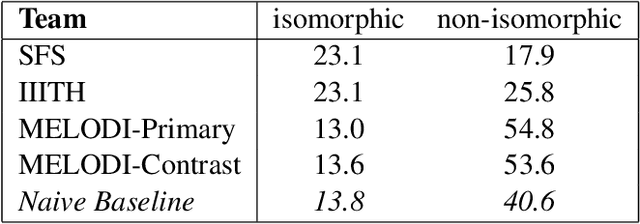
In this paper, we describe SemEval-2013 Task 4: the definition, the data, the evaluation and the results. The task is to capture some of the meaning of English noun compounds via paraphrasing. Given a two-word noun compound, the participating system is asked to produce an explicitly ranked list of its free-form paraphrases. The list is automatically compared and evaluated against a similarly ranked list of paraphrases proposed by human annotators, recruited and managed through Amazon's Mechanical Turk. The comparison of raw paraphrases is sensitive to syntactic and morphological variation. The "gold" ranking is based on the relative popularity of paraphrases among annotators. To make the ranking more reliable, highly similar paraphrases are grouped, so as to downplay superficial differences in syntax and morphology. Three systems participated in the task. They all beat a simple baseline on one of the two evaluation measures, but not on both measures. This shows that the task is difficult.
* noun compounds, paraphrasing verbs, semantic interpretation, multi-word expressions, MWEs
On the Robustness of Projection Neural Networks For Efficient Text Representation: An Empirical Study
Aug 14, 2019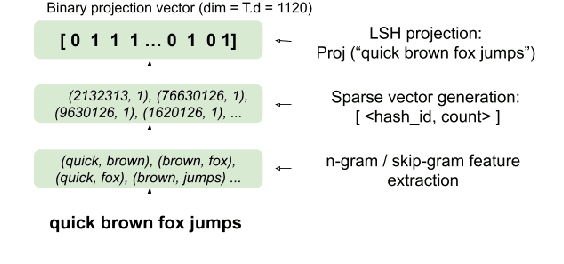
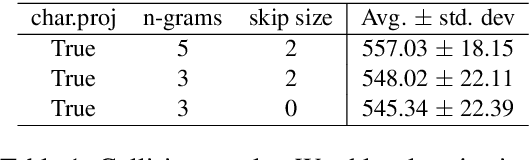
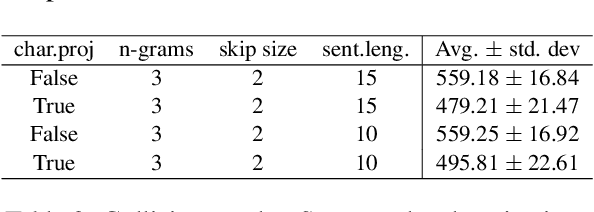
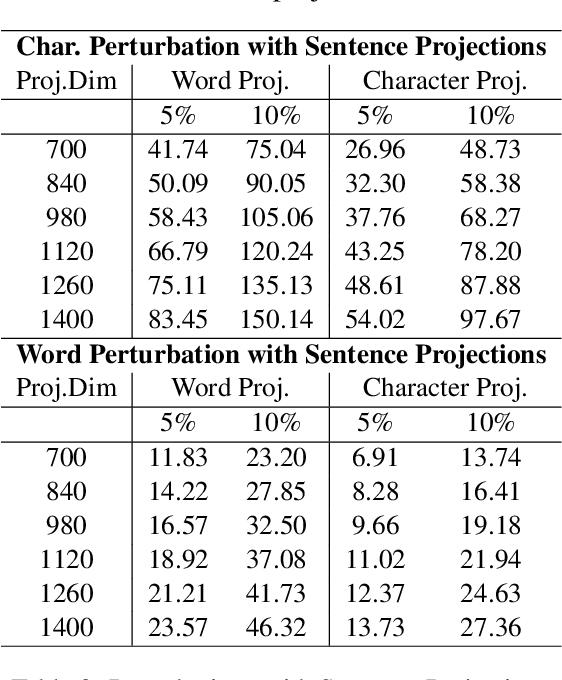
Recently, there has been strong interest in developing natural language applications that live on personal devices such as mobile phones, watches and IoT with the objective to preserve user privacy and have low memory. Advances in Locality-Sensitive Hashing (LSH)-based projection networks have demonstrated state-of-the-art performance without any embedding lookup tables and instead computing on-the-fly text representations. However, previous works have not investigated "What makes projection neural networks effective at capturing compact representations for text classification?" and "Are these projection models resistant to perturbations and misspellings in input text?". In this paper, we analyze and answer these questions through perturbation analyses and by running experiments on multiple dialog act prediction tasks. Our results show that the projections are resistant to perturbations and misspellings compared to widely-used recurrent architectures that use word embeddings. On ATIS intent prediction task, when evaluated with perturbed input data, we observe that the performance of recurrent models that use word embeddings drops significantly by more than 30% compared to just 5% with projection networks, showing that LSH-based projection representations are robust and consistently lead to high quality performance.
Transferable Neural Projection Representations
Jun 04, 2019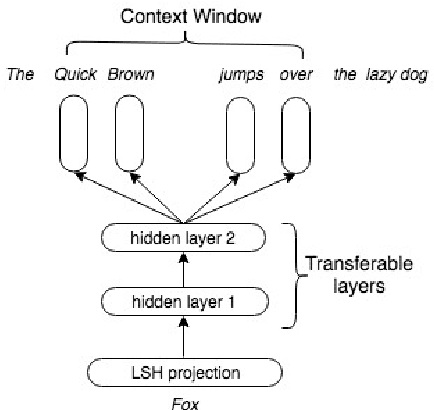
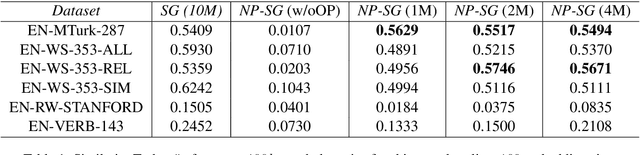

Neural word representations are at the core of many state-of-the-art natural language processing models. A widely used approach is to pre-train, store and look up word or character embedding matrices. While useful, such representations occupy huge memory making it hard to deploy on-device and often do not generalize to unknown words due to vocabulary pruning. In this paper, we propose a skip-gram based architecture coupled with Locality-Sensitive Hashing (LSH) projections to learn efficient dynamically computable representations. Our model does not need to store lookup tables as representations are computed on-the-fly and require low memory footprint. The representations can be trained in an unsupervised fashion and can be easily transferred to other NLP tasks. For qualitative evaluation, we analyze the nearest neighbors of the word representations and discover semantically similar words even with misspellings. For quantitative evaluation, we plug our transferable projections into a simple LSTM and run it on multiple NLP tasks and show how our transferable projections achieve better performance compared to prior work.
Variational Reasoning for Question Answering with Knowledge Graph
Nov 27, 2017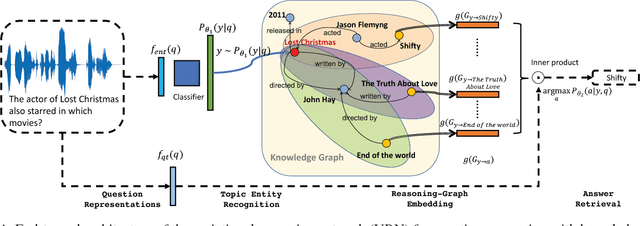

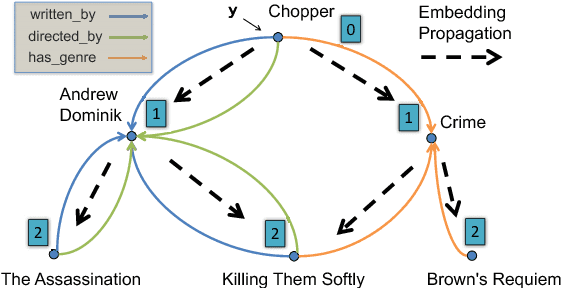

Knowledge graph (KG) is known to be helpful for the task of question answering (QA), since it provides well-structured relational information between entities, and allows one to further infer indirect facts. However, it is challenging to build QA systems which can learn to reason over knowledge graphs based on question-answer pairs alone. First, when people ask questions, their expressions are noisy (for example, typos in texts, or variations in pronunciations), which is non-trivial for the QA system to match those mentioned entities to the knowledge graph. Second, many questions require multi-hop logic reasoning over the knowledge graph to retrieve the answers. To address these challenges, we propose a novel and unified deep learning architecture, and an end-to-end variational learning algorithm which can handle noise in questions, and learn multi-hop reasoning simultaneously. Our method achieves state-of-the-art performance on a recent benchmark dataset in the literature. We also derive a series of new benchmark datasets, including questions for multi-hop reasoning, questions paraphrased by neural translation model, and questions in human voice. Our method yields very promising results on all these challenging datasets.
Neural Skill Transfer from Supervised Language Tasks to Reading Comprehension
Nov 10, 2017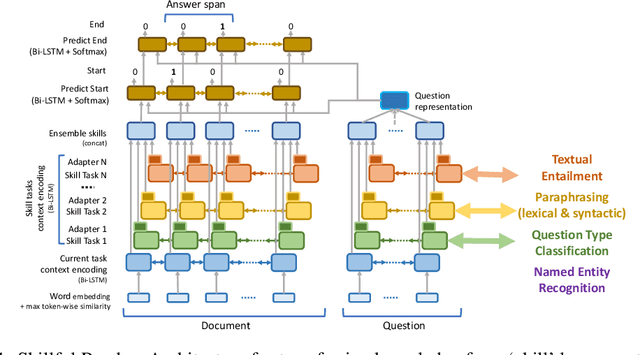
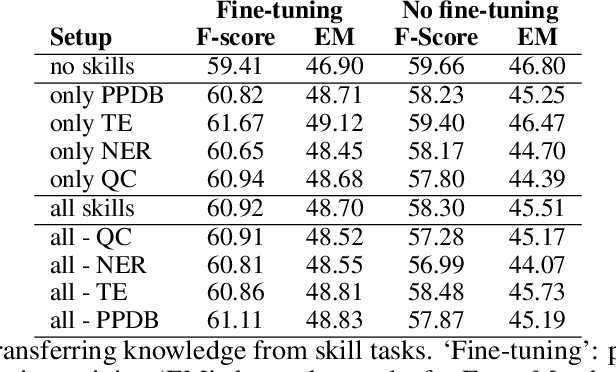
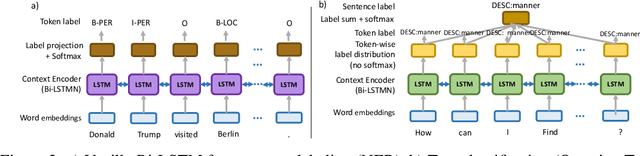
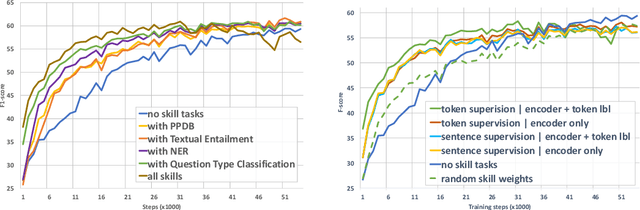
Reading comprehension is a challenging task in natural language processing and requires a set of skills to be solved. While current approaches focus on solving the task as a whole, in this paper, we propose to use a neural network `skill' transfer approach. We transfer knowledge from several lower-level language tasks (skills) including textual entailment, named entity recognition, paraphrase detection and question type classification into the reading comprehension model. We conduct an empirical evaluation and show that transferring language skill knowledge leads to significant improvements for the task with much fewer steps compared to the baseline model. We also show that the skill transfer approach is effective even with small amounts of training data. Another finding of this work is that using token-wise deep label supervision for text classification improves the performance of transfer learning.