 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemGeoNav:A Safety-Guided Visual Navigation Approach with Semantic Reasoning and Geometric Planning
Jun 15, 2026Learning-based visual navigation has enhanced semantic goal-reaching capabilities. However, due to their black-box nature, purely end-to-end models often lack explicit geometric constraints, leading to unpredictable and unreliable obstacle avoidance in open environments. Conversely, traditional geometric planners ensure safety but struggle with high-dimensional visual targets. To address these limitations, we propose SemGeoNav, a novel hierarchical visual navigation framework.It tightly integrates the high-level semantic reasoning of end-to-end models with the reliable local planning ability of geometry-based methods, achieving robust image-based navigation while significantly improving obstacle avoidance. Furthermore, we introduce a temporal trajectory smoothing mechanism to ensure continuous and stable robot motion. We evaluated SemGeoNav on a Unitree Go2 quadruped robot in real-world environments. The results demonstrate that SemGeoNav outperforms existing representative methods, including ViNT and NoMaD, achieving higher success rates and shorter navigation times.
Accelerating Vision Transformers on Brain Processing Unit
Feb 06, 2026With the advancement of deep learning technologies, specialized neural processing hardware such as Brain Processing Units (BPUs) have emerged as dedicated platforms for CNN acceleration, offering optimized INT8 computation capabilities for convolutional operations. Meanwhile, Vision Transformer (ViT) models, such as the Data-efficient Image Transformer (DeiT), have demonstrated superior performance and play increasingly crucial roles in computer vision tasks. However, due to the architectural mismatch between CNN-optimized hardware and Vision Transformer computation characteristics--namely, that linear layers in Transformers operate on three-dimensional data while BPU acceleration is designed for four-dimensional convolution operations-it is difficult or even impossible to leverage BPU's advantages when deploying Vision Transformers. To address this challenge, we propose a novel approach that restructures the Vision Transformer by replacing linear layers and layer normalization operations with carefully designed convolutional operators. This enables DeiT to fully utilize the acceleration capabilities of BPUs, while allowing the original weight parameters to be inherited by the restructured models without retraining or fine-tuning. To the best of our knowledge, this is the first successful deployment of Vision Transformers that fully leverages BPU classification datasets demonstrate the effectiveness of our approach. Specifically, the quantized DeiT-Base model achieves 80.4% accuracy on ImageNet, compared to the original 81.8%, while obtaining up to a 3.8* inference speedup. Our finetuned DeiT model on the flower classification dataset also achieves excellent performance, with only a 0.5% accuracy drop for the DeiT-Base model, further demonstrating the effectiveness of our method.
EdgeNAT: Transformer for Efficient Edge Detection
Aug 20, 2024



Transformers, renowned for their powerful feature extraction capabilities, have played an increasingly prominent role in various vision tasks. Especially, recent advancements present transformer with hierarchical structures such as Dilated Neighborhood Attention Transformer (DiNAT), demonstrating outstanding ability to efficiently capture both global and local features. However, transformers' application in edge detection has not been fully exploited. In this paper, we propose EdgeNAT, a one-stage transformer-based edge detector with DiNAT as the encoder, capable of extracting object boundaries and meaningful edges both accurately and efficiently. On the one hand, EdgeNAT captures global contextual information and detailed local cues with DiNAT, on the other hand, it enhances feature representation with a novel SCAF-MLA decoder by utilizing both inter-spatial and inter-channel relationships of feature maps. Extensive experiments on multiple datasets show that our method achieves state-of-the-art performance on both RGB and depth images. Notably, on the widely used BSDS500 dataset, our L model achieves impressive performances, with ODS F-measure and OIS F-measure of 86.0%, 87.6% for multi-scale input,and 84.9%, and 86.3% for single-scale input, surpassing the current state-of-the-art EDTER by 1.2%, 1.1%, 1.7%, and 1.6%, respectively. Moreover, as for throughput, our approach runs at 20.87 FPS on RTX 4090 GPU with single-scale input. The code for our method will be released soon.
DrugLLM: Open Large Language Model for Few-shot Molecule Generation
May 07, 2024



Large Language Models (LLMs) have made great strides in areas such as language processing and computer vision. Despite the emergence of diverse techniques to improve few-shot learning capacity, current LLMs fall short in handling the languages in biology and chemistry. For example, they are struggling to capture the relationship between molecule structure and pharmacochemical properties. Consequently, the few-shot learning capacity of small-molecule drug modification remains impeded. In this work, we introduced DrugLLM, a LLM tailored for drug design. During the training process, we employed Group-based Molecular Representation (GMR) to represent molecules, arranging them in sequences that reflect modifications aimed at enhancing specific molecular properties. DrugLLM learns how to modify molecules in drug discovery by predicting the next molecule based on past modifications. Extensive computational experiments demonstrate that DrugLLM can generate new molecules with expected properties based on limited examples, presenting a powerful few-shot molecule generation capacity.
Neural Implicit Field Editing Considering Object-environment Interaction
Nov 01, 2023



The 3D scene editing method based on neural implicit field has gained wide attention. It has achieved excellent results in 3D editing tasks. However, existing methods often blend the interaction between objects and scene environment. The change of scene appearance like shadows is failed to be displayed in the rendering view. In this paper, we propose an Object and Scene environment Interaction aware (OSI-aware) system, which is a novel two-stream neural rendering system considering object and scene environment interaction. To obtain illuminating conditions from the mixture soup, the system successfully separates the interaction between objects and scene environment by intrinsic decomposition method. To study the corresponding changes to the scene appearance from object-level editing tasks, we introduce a depth map guided scene inpainting method and shadow rendering method by point matching strategy. Extensive experiments demonstrate that our novel pipeline produce reasonable appearance changes in scene editing tasks. It also achieve competitive performance for the rendering quality in novel-view synthesis tasks.
Identification of diffracted vortex beams at different propagation distances using deep learning
Mar 30, 2022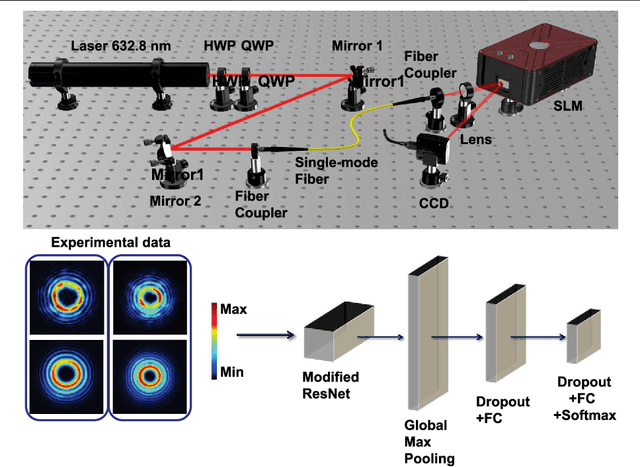
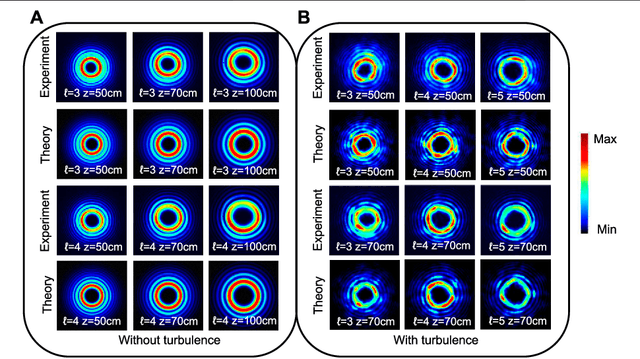
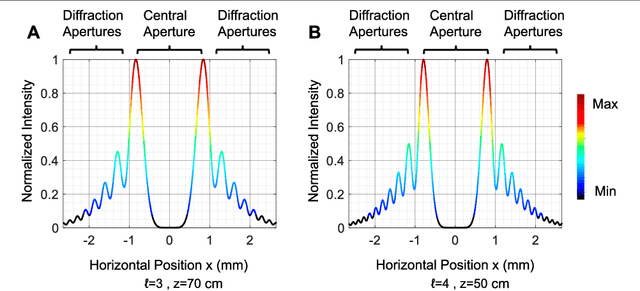
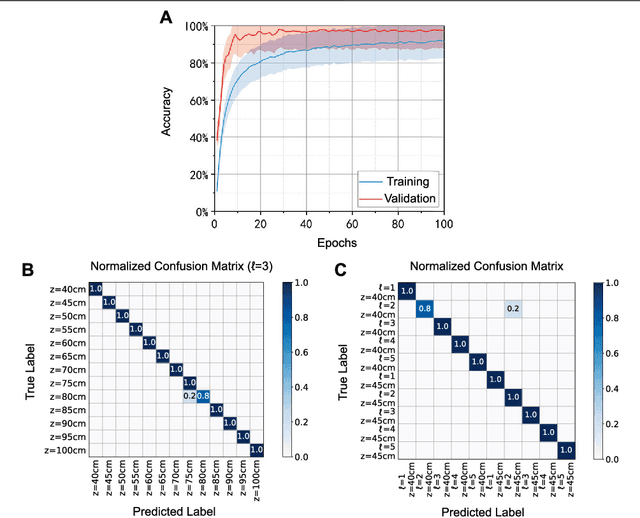
Orbital angular momentum of light is regarded as a valuable resource in quantum technology, especially in quantum communication and quantum sensing and ranging. However, the OAM state of light is susceptible to undesirable experimental conditions such as propagation distance and phase distortions, which hinders the potential for the realistic implementation of relevant technologies. In this article, we exploit an enhanced deep learning neural network to identify different OAM modes of light at multiple propagation distances with phase distortions. Specifically, our trained deep learning neural network can efficiently identify the vortex beam's topological charge and propagation distance with 97% accuracy. Our technique has important implications for OAM based communication and sensing protocols.
* 9 pages, 4 figures