 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovelty-based Tree-of-Thought Search for LLM Reasoning and Planning
May 07, 2026Although advances such as chain-of-thought, tree-of-thought or reinforcement learning have improved the performance of LLMs in reasoning and planning tasks, they are still brittle and have not achieved human-level performance in many domains, and often suffer from high time and token costs. Inspired by the success of width-based search in planning, we explore how the concept of novelty can be transferred to language domains and how it can improve tree-of-thought reasoning. A tree of thoughts relies on building possible "paths" of consecutive ideas or thoughts. These are generated by repeatedly prompting an LLM. In our paper, a measurable concept of novelty is proposed that describes the uniqueness of a new node (thought) in comparison to nodes previously seen in the search tree. Novelty is estimated by prompting an LLM and making use of embedded general knowledge from pre-training. This metric can then be used to prune branches and reduce the scope of the search. Although this method introduces more prompts per state, the overall token cost can be reduced by pruning and reducing the overall tree size. This procedure is tested and compared using several benchmarks in language-based planning and general reasoning.
SYMBOLIZER: Symbolic Model-free Task Planning with VLMs
Apr 20, 2026Traditional Task and Motion Planning (TAMP) systems depend on physics models for motion planning and discrete symbolic models for task planning. Although physics model are often available, symbolic models (consisting of symbolic state interpretation and action models) must be meticulously handcrafted or learned from labeled data. This process is both resource-intensive and constrains the solution to the specific domain, limiting scalability and adaptability. On the other hand, Visual Language Models (VLMs) show desirable zero-shot visual understanding (due to their extensive training on heterogeneous data), but still achieve limited planning capabilities. Therefore, integrating VLMs with classical planning for long-horizon reasoning in TAMP problems offers high potential. Recent works in this direction still lack generality and depend on handcrafted, task-specific solutions, e.g. describing all possible objects in advance, or using symbolic action models. We propose a framework that generalizes well to unseen problem instances. The method requires only lifted predicates describing relations among objects and uses VLMs to ground them from images to obtain the symbolic state. Planning is performed with domain-independent heuristic search using goal-count and width-based heuristics, without need for action models. Symbolic search over VLM-grounded state-space outperforms direct VLM-based planning and performs on par with approaches that use a VLM-derived heuristic. This shows that domain-independent search can effectively solve problems across domains with large combinatorial state spaces. We extensively evaluate on extensively evaluate our method and achieve state-of-the-art results on the ProDG and ViPlan benchmarks.
Search-Based Robot Motion Planning With Distance-Based Adaptive Motion Primitives
Jul 01, 2025This work proposes a motion planning algorithm for robotic manipulators that combines sampling-based and search-based planning methods. The core contribution of the proposed approach is the usage of burs of free configuration space (C-space) as adaptive motion primitives within the graph search algorithm. Due to their feature to adaptively expand in free C-space, burs enable more efficient exploration of the configuration space compared to fixed-sized motion primitives, significantly reducing the time to find a valid path and the number of required expansions. The algorithm is implemented within the existing SMPL (Search-Based Motion Planning Library) library and evaluated through a series of different scenarios involving manipulators with varying number of degrees-of-freedom (DoF) and environment complexity. Results demonstrate that the bur-based approach outperforms fixed-primitive planning in complex scenarios, particularly for high DoF manipulators, while achieving comparable performance in simpler scenarios.
Search-based versus Sampling-based Robot Motion Planning: A Comparative Study
Jun 17, 2024



Robot motion planning is a challenging domain as it involves dealing with high-dimensional and continuous search space. In past decades, a wide variety of planning algorithms have been developed to tackle this problem, sometimes in isolation without comparing to each other. In this study, we benchmark two such prominent types of algorithms: OMPL's sampling-based RRT-Connect and SMPL's search-based ARA* with motion primitives. To compare these two fundamentally different approaches fairly, we adapt them to ensure the same planning conditions and benchmark them on the same set of planning scenarios. Our findings suggest that sampling-based planners like RRT-Connect show more consistent performance across the board in high-dimensional spaces, whereas search-based planners like ARA* have the capacity to perform significantly better when used with a suitable action-space sampling scheme. Through this study, we hope to showcase the effort required to properly benchmark motion planners from different paradigms thereby contributing to a more nuanced understanding of their capabilities and limitations. The code is available at https://github.com/gsotirchos/benchmarking_planners
SLOPE: Search with Learned Optimal Pruning-based Expansion
Jun 07, 2024Heuristic search is often used for motion planning and pathfinding problems, for finding the shortest path in a graph while also promising completeness and optimal efficiency. The drawback is it's space complexity, specifically storing all expanded child nodes in memory and sorting large lists of active nodes, which can be a problem in real-time scenarios with limited on-board computation. To combat this, we present the Search with Learned Optimal Pruning-based Expansion (SLOPE), which, learns the distance of a node from a possible optimal path, unlike other approaches that learn a cost-to-go value. The unfavored nodes are then pruned according to the said distance, which in turn reduces the size of the open list. This ensures that the search explores only the region close to optimal paths while lowering memory and computational costs. Unlike traditional learning methods, our approach is orthogonal to estimating cost-to-go heuristics, offering a complementary strategy for improving search efficiency. We demonstrate the effectiveness of our approach evaluating it as a standalone search method and in conjunction with learned heuristic functions, achieving comparable-or-better node expansion metrics, while lowering the number of child nodes in the open list. Our code is available at https://github.com/dbokan1/SLOPE.
ExploRLLM: Guiding Exploration in Reinforcement Learning with Large Language Models
Mar 15, 2024



In image-based robot manipulation tasks with large observation and action spaces, reinforcement learning struggles with low sample efficiency, slow training speed, and uncertain convergence. As an alternative, large pre-trained foundation models have shown promise in robotic manipulation, particularly in zero-shot and few-shot applications. However, using these models directly is unreliable due to limited reasoning capabilities and challenges in understanding physical and spatial contexts. This paper introduces ExploRLLM, a novel approach that leverages the inductive bias of foundation models (e.g. Large Language Models) to guide exploration in reinforcement learning. We also exploit these foundation models to reformulate the action and observation spaces to enhance the training efficiency in reinforcement learning. Our experiments demonstrate that guided exploration enables much quicker convergence than training without it. Additionally, we validate that ExploRLLM outperforms vanilla foundation model baselines and that the policy trained in simulation can be applied in real-world settings without additional training.
PARTNR: Pick and place Ambiguity Resolving by Trustworthy iNteractive leaRning
Nov 15, 2022Several recent works show impressive results in mapping language-based human commands and image scene observations to direct robot executable policies (e.g., pick and place poses). However, these approaches do not consider the uncertainty of the trained policy and simply always execute actions suggested by the current policy as the most probable ones. This makes them vulnerable to domain shift and inefficient in the number of required demonstrations. We extend previous works and present the PARTNR algorithm that can detect ambiguities in the trained policy by analyzing multiple modalities in the pick and place poses using topological analysis. PARTNR employs an adaptive, sensitivity-based, gating function that decides if additional user demonstrations are required. User demonstrations are aggregated to the dataset and used for subsequent training. In this way, the policy can adapt promptly to domain shift and it can minimize the number of required demonstrations for a well-trained policy. The adaptive threshold enables to achieve the user-acceptable level of ambiguity to execute the policy autonomously and in turn, increase the trustworthiness of our system. We demonstrate the performance of PARTNR in a table-top pick and place task.
Overview of Tools Supporting Planning for Automated Driving
Mar 09, 2020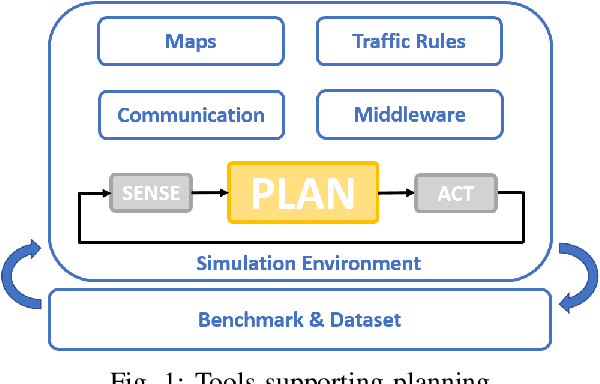
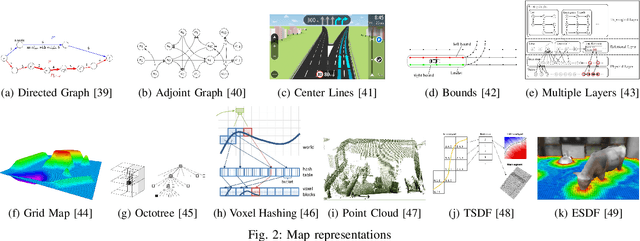
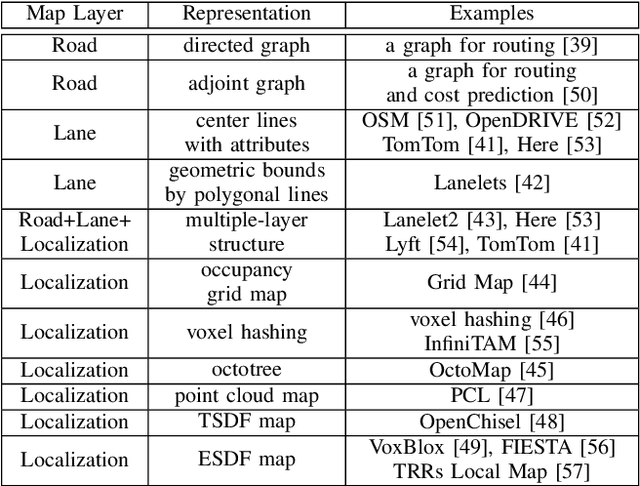
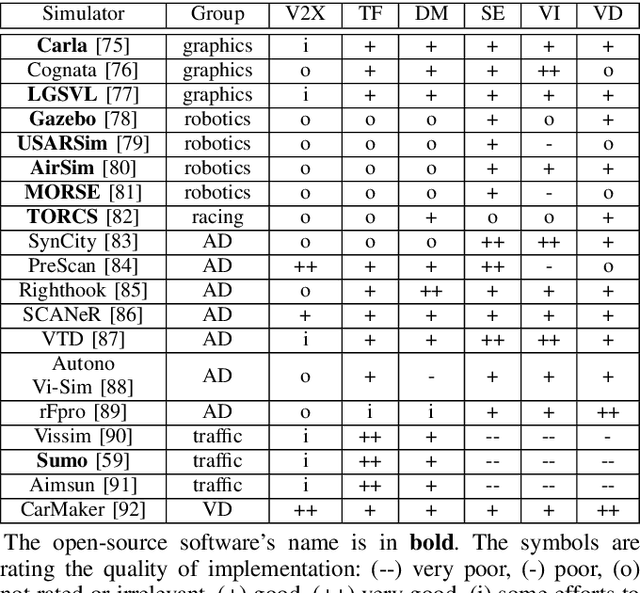
Planning is an essential topic in the realm of automated driving. Besides planning algorithms that are widely covered in the literature, planning requires different software tools for its development, validation, and execution. This paper presents a survey of such tools including map representations, communication, traffic rules, open-source planning stacks and middleware, simulation, and visualization tools as well as benchmarks. We start by defining the planning task and different supporting tools. Next, we provide a comprehensive review of state-of-the-art developments and analysis of relations among them. Finally, we discuss the current gaps and suggest future research directions.
Search-Based Motion Planning for Performance Autonomous Driving
Jul 18, 2019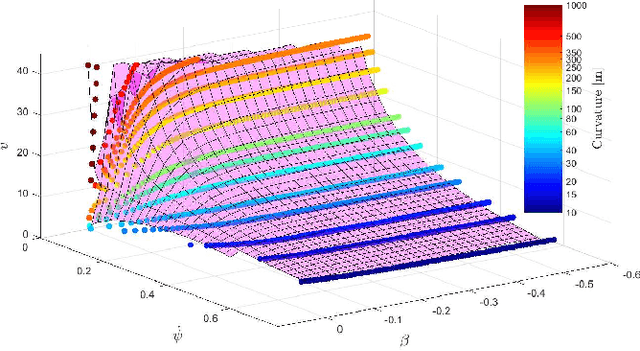
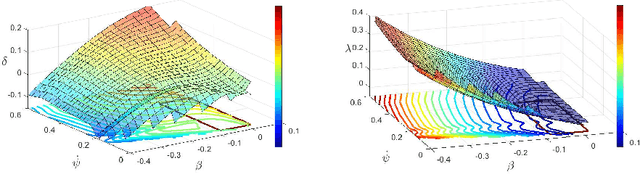
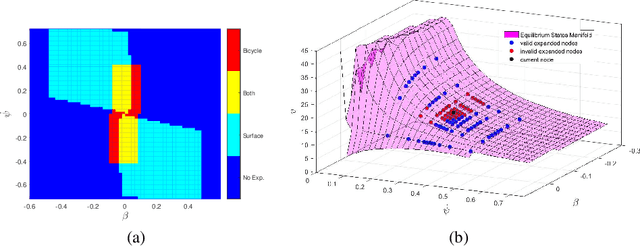
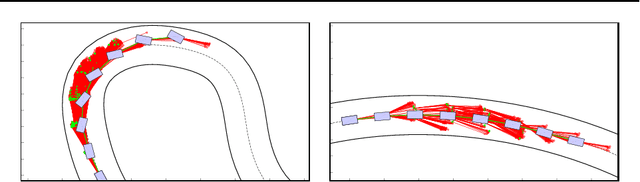
Driving on the limits of vehicle dynamics requires predictive planning of future vehicle states. In this work, a search-based motion planning is used to generate suitable reference trajectories of dynamic vehicle states with the goal to achieve the minimum lap time on slippery roads. The search-based approach enables to explicitly consider a nonlinear vehicle dynamics model as well as constraints on states and inputs so that even challenging scenarios can be achieved in a safe and optimal way. The algorithm performance is evaluated in simulated driving on a track with segments of different curvatures.
A novel approach to model exploration for value function learning
Jun 06, 2019
Planning and Learning are complementary approaches. Planning relies on deliberative reasoning about the current state and sequence of future reachable states to solve the problem. Learning, on the other hand, is focused on improving system performance based on experience or available data. Learning to improve the performance of planning based on experience in similar, previously solved problems, is ongoing research. One approach is to learn Value function (cost-to-go) which can be used as heuristics for speeding up search-based planning. Existing approaches in this direction use the results of the previous search for learning the heuristics. In this work, we present a search-inspired approach of systematic model exploration for the learning of the value function which does not stop when a plan is available but rather prolongs search such that not only resulting optimal path is used but also extended region around the optimal path. This, in turn, improves both the efficiency and robustness of successive planning. Additionally, the effect of losing admissibility by using ML heuristic is managed by bounding ML with other admissible heuristics.