 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaRaFFusion: Improving 2D Semantic Segmentation with Camera-Radar Point Cloud Fusion and Zero-Shot Image Inpainting
May 06, 2025Segmenting objects in an environment is a crucial task for autonomous driving and robotics, as it enables a better understanding of the surroundings of each agent. Although camera sensors provide rich visual details, they are vulnerable to adverse weather conditions. In contrast, radar sensors remain robust under such conditions, but often produce sparse and noisy data. Therefore, a promising approach is to fuse information from both sensors. In this work, we propose a novel framework to enhance camera-only baselines by integrating a diffusion model into a camera-radar fusion architecture. We leverage radar point features to create pseudo-masks using the Segment-Anything model, treating the projected radar points as point prompts. Additionally, we propose a noise reduction unit to denoise these pseudo-masks, which are further used to generate inpainted images that complete the missing information in the original images. Our method improves the camera-only segmentation baseline by 2.63% in mIoU and enhances our camera-radar fusion architecture by 1.48% in mIoU on the Waterscenes dataset. This demonstrates the effectiveness of our approach for semantic segmentation using camera-radar fusion under adverse weather conditions.
Enhanced Radar Perception via Multi-Task Learning: Towards Refined Data for Sensor Fusion Applications
Apr 09, 2024Radar and camera fusion yields robustness in perception tasks by leveraging the strength of both sensors. The typical extracted radar point cloud is 2D without height information due to insufficient antennas along the elevation axis, which challenges the network performance. This work introduces a learning-based approach to infer the height of radar points associated with 3D objects. A novel robust regression loss is introduced to address the sparse target challenge. In addition, a multi-task training strategy is employed, emphasizing important features. The average radar absolute height error decreases from 1.69 to 0.25 meters compared to the state-of-the-art height extension method. The estimated target height values are used to preprocess and enrich radar data for downstream perception tasks. Integrating this refined radar information further enhances the performance of existing radar camera fusion models for object detection and depth estimation tasks.
Multi-Task Cross-Modality Attention-Fusion for 2D Object Detection
Jul 17, 2023



Accurate and robust object detection is critical for autonomous driving. Image-based detectors face difficulties caused by low visibility in adverse weather conditions. Thus, radar-camera fusion is of particular interest but presents challenges in optimally fusing heterogeneous data sources. To approach this issue, we propose two new radar preprocessing techniques to better align radar and camera data. In addition, we introduce a Multi-Task Cross-Modality Attention-Fusion Network (MCAF-Net) for object detection, which includes two new fusion blocks. These allow for exploiting information from the feature maps more comprehensively. The proposed algorithm jointly detects objects and segments free space, which guides the model to focus on the more relevant part of the scene, namely, the occupied space. Our approach outperforms current state-of-the-art radar-camera fusion-based object detectors in the nuScenes dataset and achieves more robust results in adverse weather conditions and nighttime scenarios.
Overview of Tools Supporting Planning for Automated Driving
Mar 09, 2020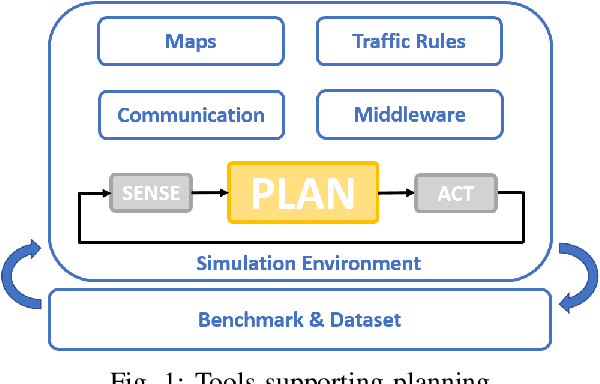
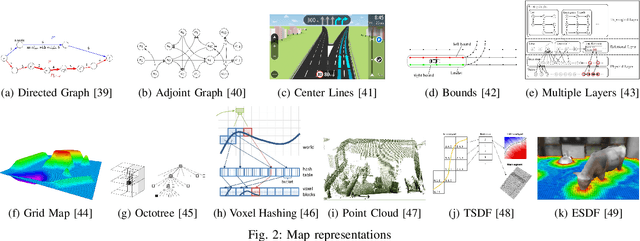
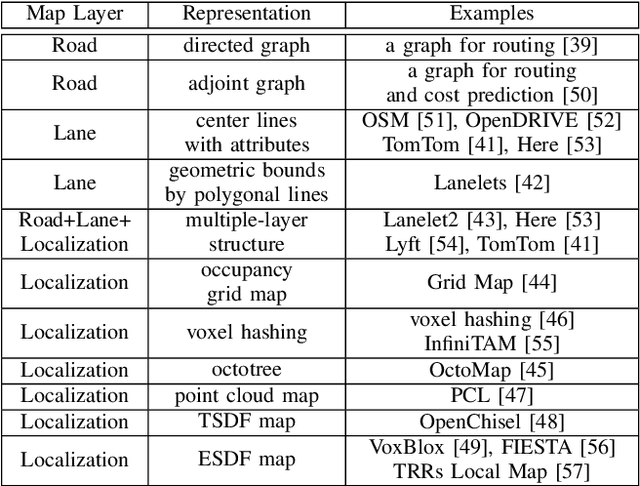
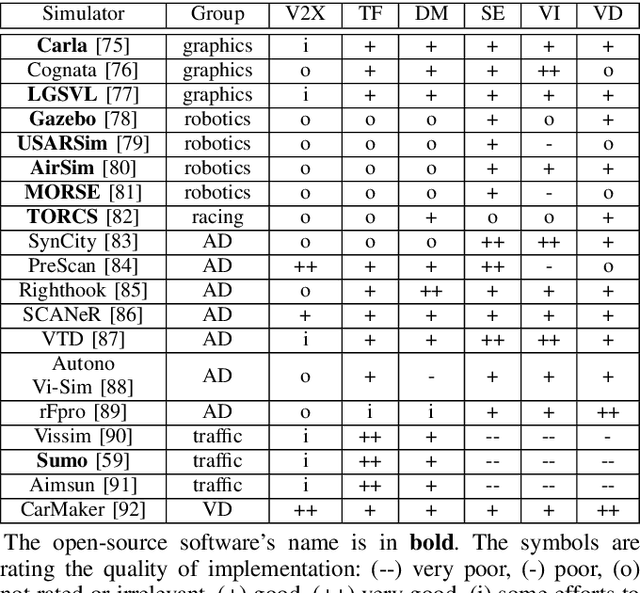
Planning is an essential topic in the realm of automated driving. Besides planning algorithms that are widely covered in the literature, planning requires different software tools for its development, validation, and execution. This paper presents a survey of such tools including map representations, communication, traffic rules, open-source planning stacks and middleware, simulation, and visualization tools as well as benchmarks. We start by defining the planning task and different supporting tools. Next, we provide a comprehensive review of state-of-the-art developments and analysis of relations among them. Finally, we discuss the current gaps and suggest future research directions.
Search-Based Motion Planning for Performance Autonomous Driving
Jul 18, 2019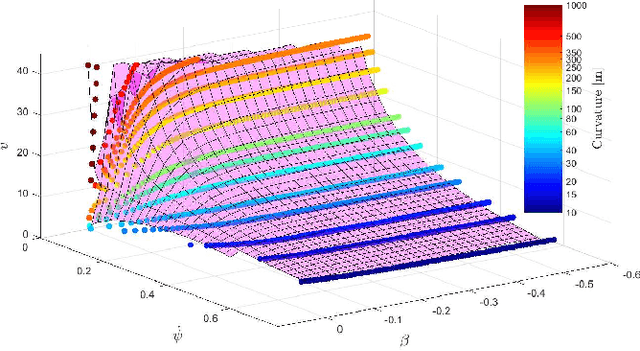
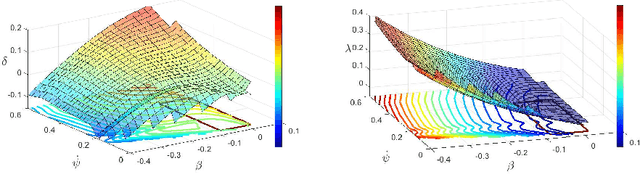
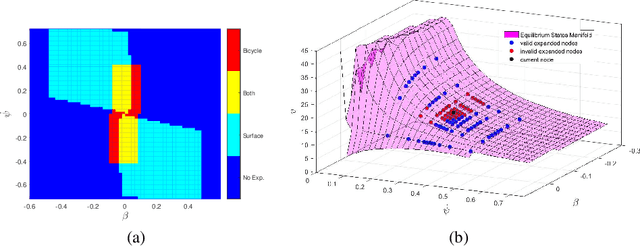
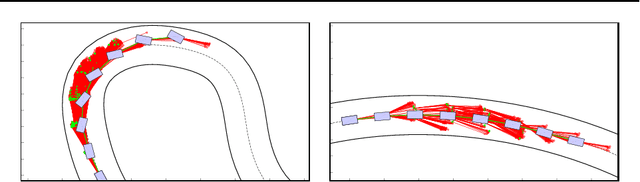
Driving on the limits of vehicle dynamics requires predictive planning of future vehicle states. In this work, a search-based motion planning is used to generate suitable reference trajectories of dynamic vehicle states with the goal to achieve the minimum lap time on slippery roads. The search-based approach enables to explicitly consider a nonlinear vehicle dynamics model as well as constraints on states and inputs so that even challenging scenarios can be achieved in a safe and optimal way. The algorithm performance is evaluated in simulated driving on a track with segments of different curvatures.
Safe learning-based optimal motion planning for automated driving
Jun 13, 2018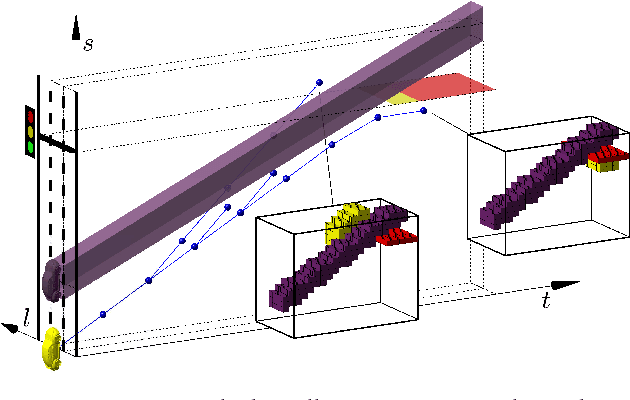
This paper presents preliminary work on learning the search heuristic for the optimal motion planning for automated driving in urban traffic. Previous work considered search-based optimal motion planning framework (SBOMP) that utilized numerical or model-based heuristics that did not consider dynamic obstacles. Optimal solution was still guaranteed since dynamic obstacles can only increase the cost. However, significant variations in the search efficiency are observed depending whether dynamic obstacles are present or not. This paper introduces machine learning (ML) based heuristic that takes into account dynamic obstacles, thus adding to the performance consistency for achieving real-time implementation.