 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Errors Are Equal: Consequence-Aware Reasoning Compute Allocation
Jun 03, 2026Modern reasoning models can allocate different amounts of test-time computation, such as thinking tokens, model calls, or compute budget, to different tasks. Existing methods generally drive this allocation by predicted difficulty and spend more compute where it is expected to raise accuracy. This implicitly assumes that all failures cost the same, since an accuracy objective weights every task equally. However, such an assumption does not hold in deployment: A typo in a log message and a migration that corrupts a production database both count as one benchmark failure, but their real-world costs are fundamentally different. To fill this gap, we propose consequence-aware test-time compute allocation. Instead of routing compute only by predicted difficulty, we use a lightweight predictor to estimate from the issue text how costly a task would be if solved incorrectly. The scheduler then routes higher-consequence tasks to larger compute tiers or higher thinking budgets under the same total budget. We conduct main experiments on SWE-bench Lite and evaluate cross-dataset behavior on Multi-SWE-bench mini, covering 700 software-engineering tasks in total. Our results reveal that consequence and difficulty are approximately orthogonal under various annotations, and that current thinking models do not allocate compute sufficiently according to consequence. Moreover, our issue-only predictor never misclassifies a high-consequence task as low-consequence across the 300 SWE-bench tasks. Under matched compute budgets, our consequence-aware scheduler reduces cost-weighted loss by 22% to 33% relative to difficulty-aware routing; in particular, the priority-aware variant, which routes by per-task cost scaled by the marginal-utility signal, crosses 30%, and its deployable predictor-driven version retains over 90% of the oracle gain.
Dynamic Importance in Diffusion U-Net for Enhanced Image Synthesis
Apr 04, 2025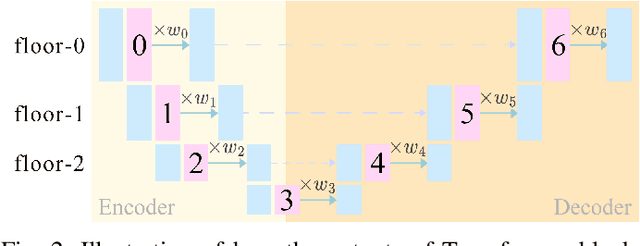
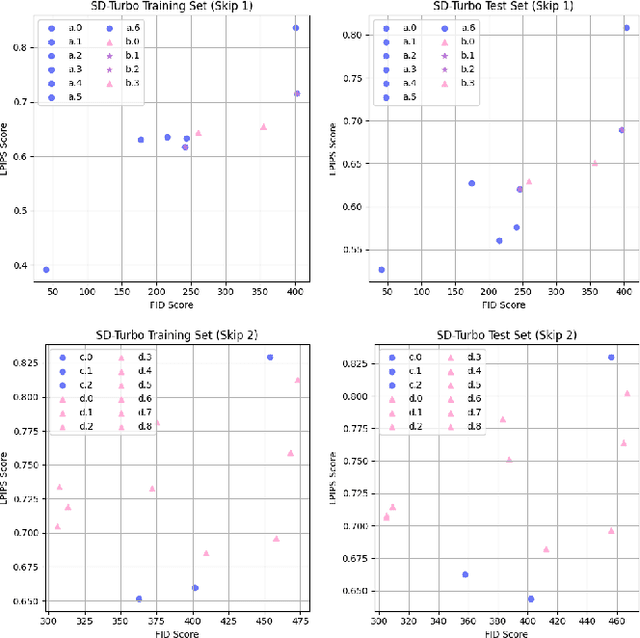
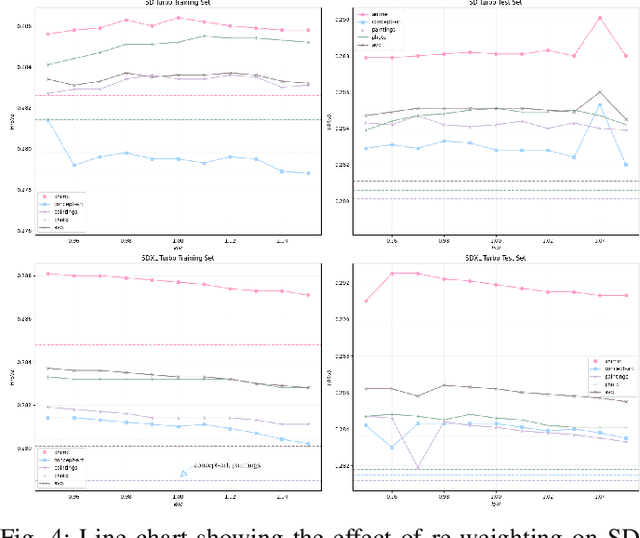
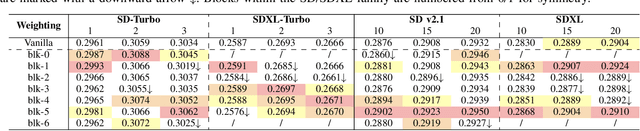
Traditional diffusion models typically employ a U-Net architecture. Previous studies have unveiled the roles of attention blocks in the U-Net. However, they overlook the dynamic evolution of their importance during the inference process, which hinders their further exploitation to improve image applications. In this study, we first theoretically proved that, re-weighting the outputs of the Transformer blocks within the U-Net is a "free lunch" for improving the signal-to-noise ratio during the sampling process. Next, we proposed Importance Probe to uncover and quantify the dynamic shifts in importance of the Transformer blocks throughout the denoising process. Finally, we design an adaptive importance-based re-weighting schedule tailored to specific image generation and editing tasks. Experimental results demonstrate that, our approach significantly improves the efficiency of the inference process, and enhances the aesthetic quality of the samples with identity consistency. Our method can be seamlessly integrated into any U-Net-based architecture. Code: https://github.com/Hytidel/UNetReweighting
SP$^2$T: Sparse Proxy Attention for Dual-stream Point Transformer
Dec 16, 2024



In 3D understanding, point transformers have yielded significant advances in broadening the receptive field. However, further enhancement of the receptive field is hindered by the constraints of grouping attention. The proxy-based model, as a hot topic in image and language feature extraction, uses global or local proxies to expand the model's receptive field. But global proxy-based methods fail to precisely determine proxy positions and are not suited for tasks like segmentation and detection in the point cloud, and exist local proxy-based methods for image face difficulties in global-local balance, proxy sampling in various point clouds, and parallel cross-attention computation for sparse association. In this paper, we present SP$^2$T, a local proxy-based dual stream point transformer, which promotes global receptive field while maintaining a balance between local and global information. To tackle robust 3D proxy sampling, we propose a spatial-wise proxy sampling with vertex-based point proxy associations, ensuring robust point-cloud sampling in many scales of point cloud. To resolve economical association computation, we introduce sparse proxy attention combined with table-based relative bias, which enables low-cost and precise interactions between proxy and point features. Comprehensive experiments across multiple datasets reveal that our model achieves SOTA performance in downstream tasks. The code has been released in https://github.com/TerenceWallel/Sparse-Proxy-Point-Transformer .
Dynamic Clustering and Cluster Contrastive Learning for Unsupervised Person Re-identification
Mar 13, 2023Unsupervised Re-ID methods aim at learning robust and discriminative features from unlabeled data. However, existing methods often ignore the relationship between module parameters of Re-ID framework and feature distributions, which may lead to feature misalignment and hinder the model performance. To address this problem, we propose a dynamic clustering and cluster contrastive learning (DCCC) method. Specifically, we first design a dynamic clustering parameters scheduler (DCPS) which adjust the hyper-parameter of clustering to fit the variation of intra- and inter-class distances. Then, a dynamic cluster contrastive learning (DyCL) method is designed to match the cluster representation vectors' weights with the local feature association. Finally, a label smoothing soft contrastive loss ($L_{ss}$) is built to keep the balance between cluster contrastive learning and self-supervised learning with low computational consumption and high computational efficiency. Experiments on several widely used public datasets validate the effectiveness of our proposed DCCC which outperforms previous state-of-the-art methods by achieving the best performance.