 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXMP-Font: Self-Supervised Cross-Modality Pre-training for Few-Shot Font Generation
Apr 11, 2022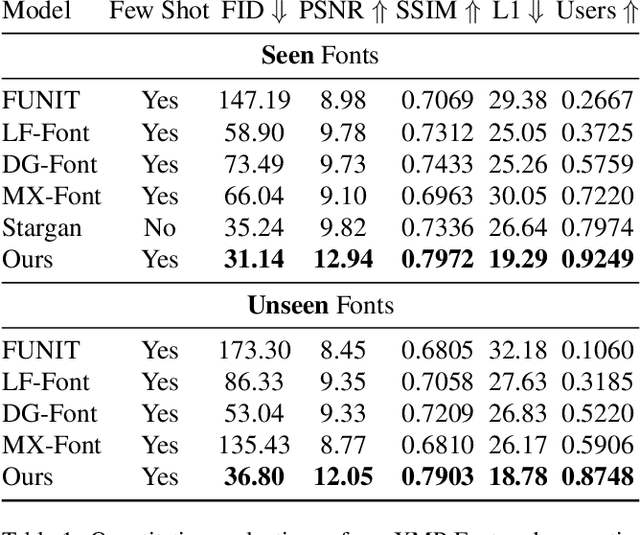
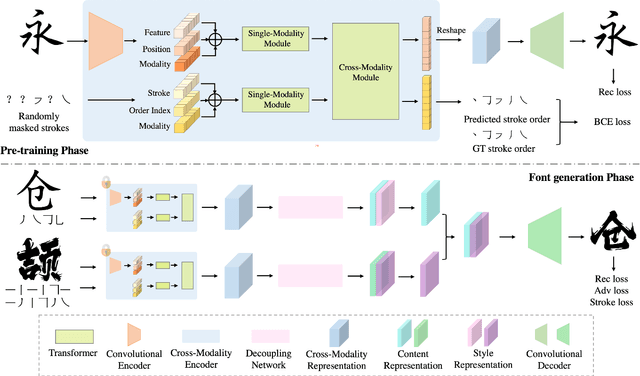
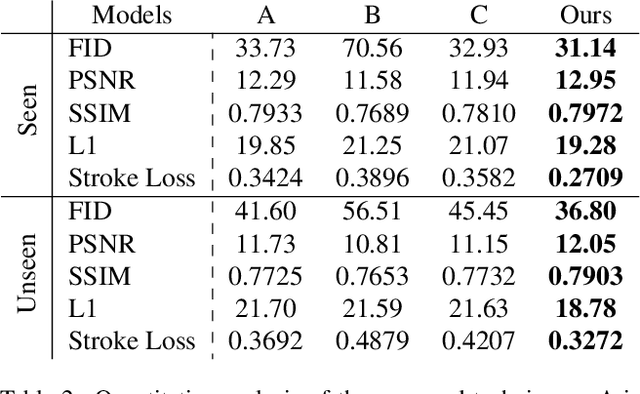
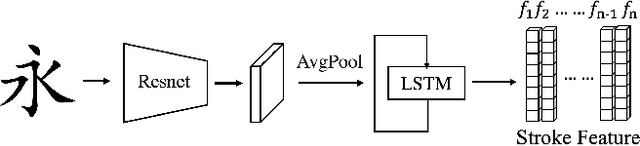
Generating a new font library is a very labor-intensive and time-consuming job for glyph-rich scripts. Few-shot font generation is thus required, as it requires only a few glyph references without fine-tuning during test. Existing methods follow the style-content disentanglement paradigm and expect novel fonts to be produced by combining the style codes of the reference glyphs and the content representations of the source. However, these few-shot font generation methods either fail to capture content-independent style representations, or employ localized component-wise style representations, which is insufficient to model many Chinese font styles that involve hyper-component features such as inter-component spacing and "connected-stroke". To resolve these drawbacks and make the style representations more reliable, we propose a self-supervised cross-modality pre-training strategy and a cross-modality transformer-based encoder that is conditioned jointly on the glyph image and the corresponding stroke labels. The cross-modality encoder is pre-trained in a self-supervised manner to allow effective capture of cross- and intra-modality correlations, which facilitates the content-style disentanglement and modeling style representations of all scales (stroke-level, component-level and character-level). The pre-trained encoder is then applied to the downstream font generation task without fine-tuning. Experimental comparisons of our method with state-of-the-art methods demonstrate our method successfully transfers styles of all scales. In addition, it only requires one reference glyph and achieves the lowest rate of bad cases in the few-shot font generation task 28% lower than the second best
Region-Aware Face Swapping
Mar 18, 2022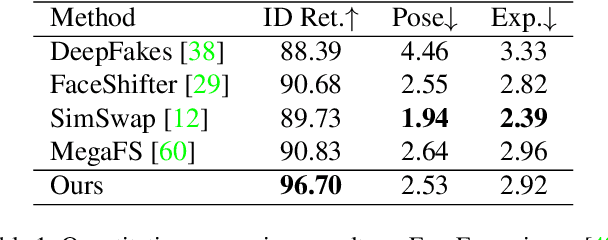
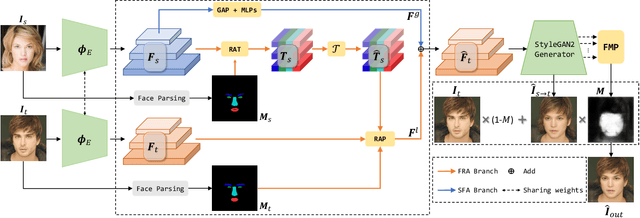

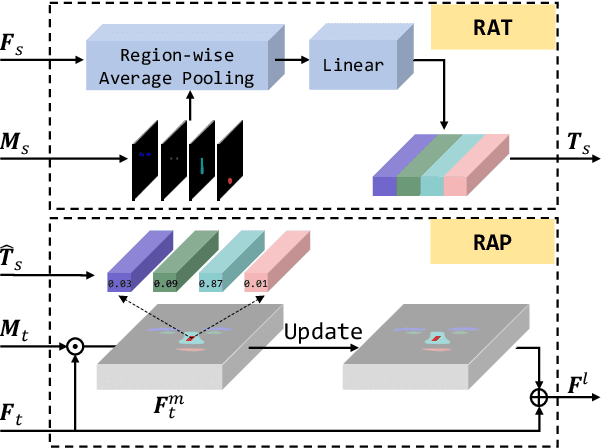
This paper presents a novel Region-Aware Face Swapping (RAFSwap) network to achieve identity-consistent harmonious high-resolution face generation in a local-global manner: \textbf{1)} Local Facial Region-Aware (FRA) branch augments local identity-relevant features by introducing the Transformer to effectively model misaligned cross-scale semantic interaction. \textbf{2)} Global Source Feature-Adaptive (SFA) branch further complements global identity-relevant cues for generating identity-consistent swapped faces. Besides, we propose a \textit{Face Mask Predictor} (FMP) module incorporated with StyleGAN2 to predict identity-relevant soft facial masks in an unsupervised manner that is more practical for generating harmonious high-resolution faces. Abundant experiments qualitatively and quantitatively demonstrate the superiority of our method for generating more identity-consistent high-resolution swapped faces over SOTA methods, \eg, obtaining 96.70 ID retrieval that outperforms SOTA MegaFS by 5.87$\uparrow$.
CLIP-GEN: Language-Free Training of a Text-to-Image Generator with CLIP
Mar 01, 2022
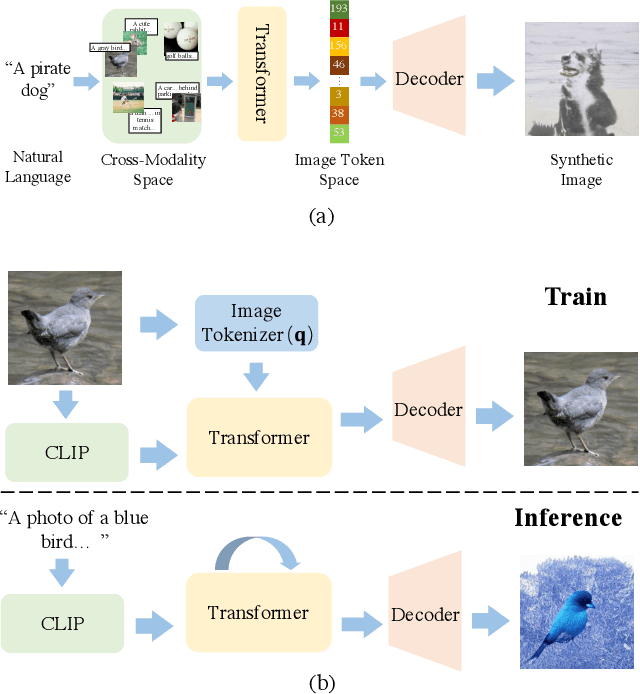
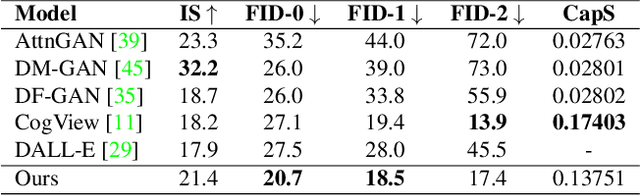
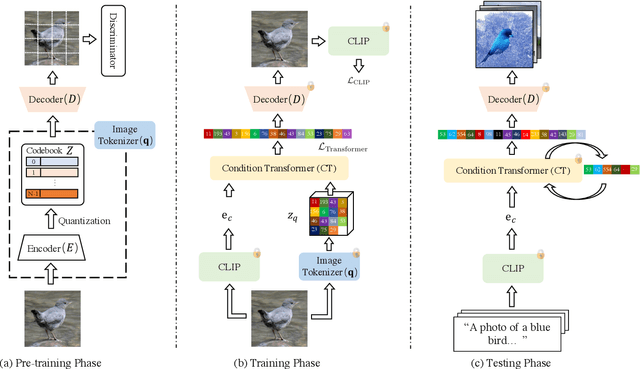
Training a text-to-image generator in the general domain (e.g., Dall.e, CogView) requires huge amounts of paired text-image data, which is too expensive to collect. In this paper, we propose a self-supervised scheme named as CLIP-GEN for general text-to-image generation with the language-image priors extracted with a pre-trained CLIP model. In our approach, we only require a set of unlabeled images in the general domain to train a text-to-image generator. Specifically, given an image without text labels, we first extract the embedding of the image in the united language-vision embedding space with the image encoder of CLIP. Next, we convert the image into a sequence of discrete tokens in the VQGAN codebook space (the VQGAN model can be trained with the unlabeled image dataset in hand). Finally, we train an autoregressive transformer that maps the image tokens from its unified language-vision representation. Once trained, the transformer can generate coherent image tokens based on the text embedding extracted from the text encoder of CLIP upon an input text. Such a strategy enables us to train a strong and general text-to-image generator with large text-free image dataset such as ImageNet. Qualitative and quantitative evaluations verify that our method significantly outperforms optimization-based text-to-image methods in terms of image quality while not compromising the text-image matching. Our method can even achieve comparable performance as flagship supervised models like CogView.
Spatial-Temporal Residual Aggregation for High Resolution Video Inpainting
Nov 05, 2021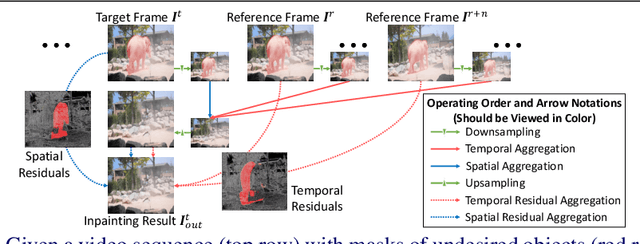
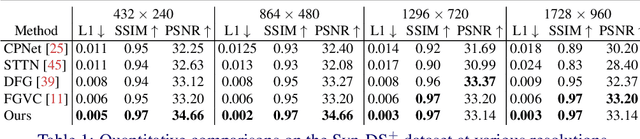
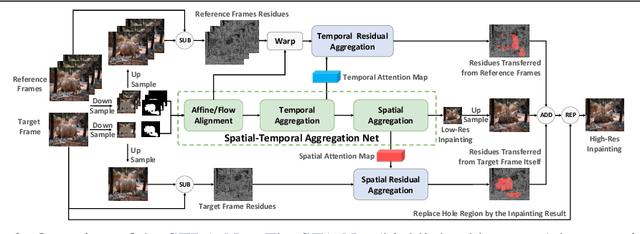
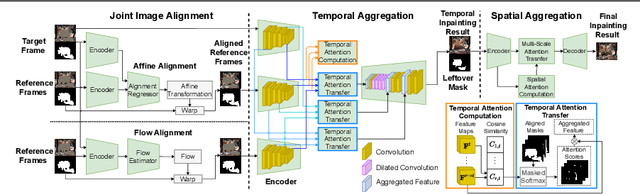
Recent learning-based inpainting algorithms have achieved compelling results for completing missing regions after removing undesired objects in videos. To maintain the temporal consistency among the frames, 3D spatial and temporal operations are often heavily used in the deep networks. However, these methods usually suffer from memory constraints and can only handle low resolution videos. We propose STRA-Net, a novel spatial-temporal residual aggregation framework for high resolution video inpainting. The key idea is to first learn and apply a spatial and temporal inpainting network on the downsampled low resolution videos. Then, we refine the low resolution results by aggregating the learned spatial and temporal image residuals (details) to the upsampled inpainted frames. Both the quantitative and qualitative evaluations show that we can produce more temporal-coherent and visually appealing results than the state-of-the-art methods on inpainting high resolution videos.
FaceEraser: Removing Facial Parts for Augmented Reality
Sep 22, 2021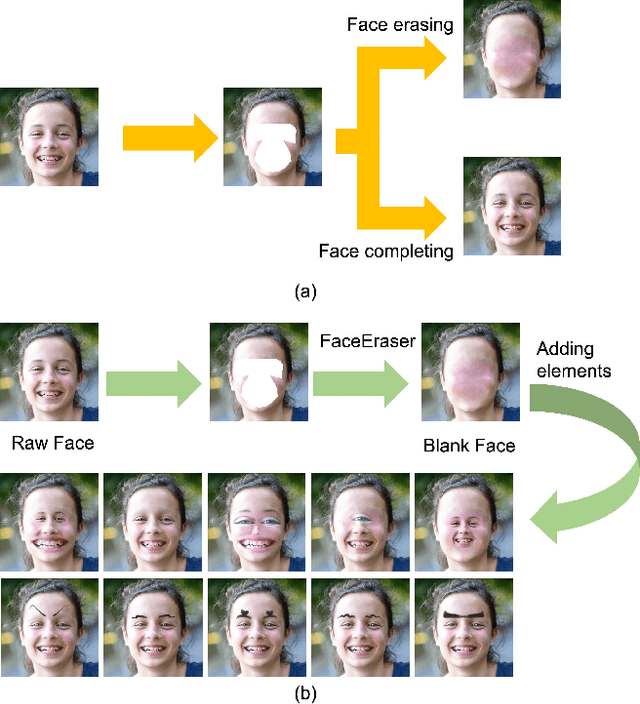
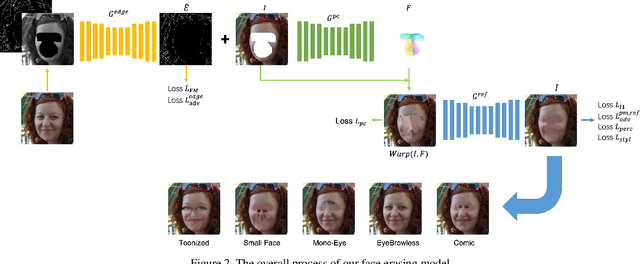
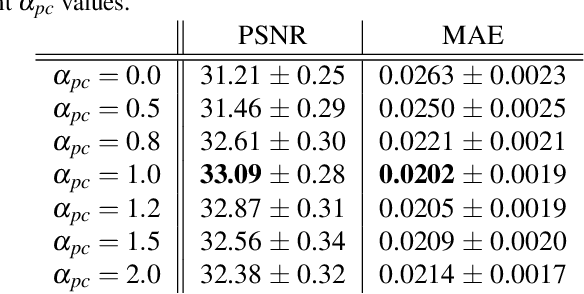
Our task is to remove all facial parts (e.g., eyebrows, eyes, mouth and nose), and then impose visual elements onto the ``blank'' face for augmented reality. Conventional object removal methods rely on image inpainting techniques (e.g., EdgeConnect, HiFill) that are trained in a self-supervised manner with randomly manipulated image pairs. Specifically, given a set of natural images, randomly masked images are used as inputs and the raw images are treated as ground truths. Whereas, this technique does not satisfy the requirements of facial parts removal, as it is hard to obtain ``ground-truth'' images with real ``blank'' faces. To address this issue, we propose a novel data generation technique to produce paired training data that well mimic the ``blank'' faces. In the mean time, we propose a novel network architecture for improved inpainting quality for our task. Finally, we demonstrate various face-oriented augmented reality applications on top of our facial parts removal model. Our method has been integrated into commercial products and its effectiveness has been verified with unconstrained user inputs. The source codes, pre-trained models and training data will be released for research purposes.
DyStyle: Dynamic Neural Network for Multi-Attribute-Conditioned Style Editing
Sep 22, 2021
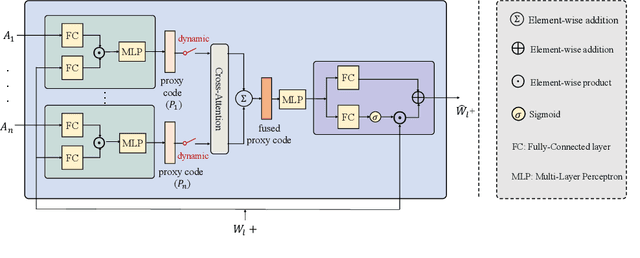
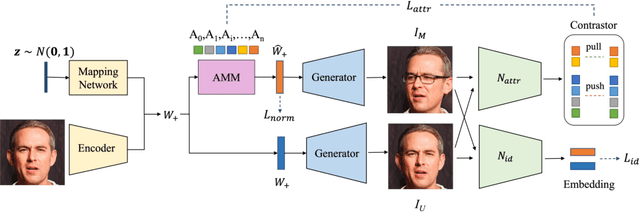
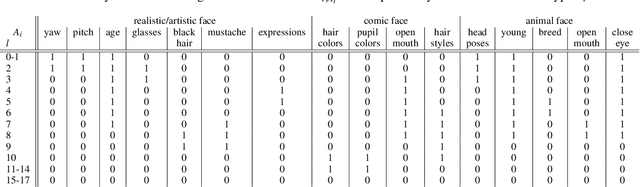
Great diversity and photorealism have been achieved by unconditional GAN frameworks such as StyleGAN and its variations. In the meantime, persistent efforts have been made to enhance the semantic controllability of StyleGANs. For example, a dozen of style manipulation methods have been recently proposed to perform attribute-conditioned style editing. Although some of these methods work well in manipulating the style codes along one attribute, the control accuracy when jointly manipulating multiple attributes tends to be problematic. To address these limitations, we propose a Dynamic Style Manipulation Network (DyStyle) whose structure and parameters vary by input samples, to perform nonlinear and adaptive manipulation of latent codes for flexible and precise attribute control. Additionally, a novel easy-to-hard training procedure is introduced for efficient and stable training of the DyStyle network. Extensive experiments have been conducted on faces and other objects. As a result, our approach demonstrates fine-grained disentangled edits along multiple numeric and binary attributes. Qualitative and quantitative comparisons with existing style manipulation methods verify the superiority of our method in terms of the attribute control accuracy and identity preservation without compromising the photorealism. The advantage of our method is even more significant for joint multi-attribute control. The source codes are made publicly available at \href{https://github.com/phycvgan/DyStyle}{phycvgan/DyStyle}.
Animating Through Warping: an Efficient Method for High-Quality Facial Expression Animation
Aug 01, 2020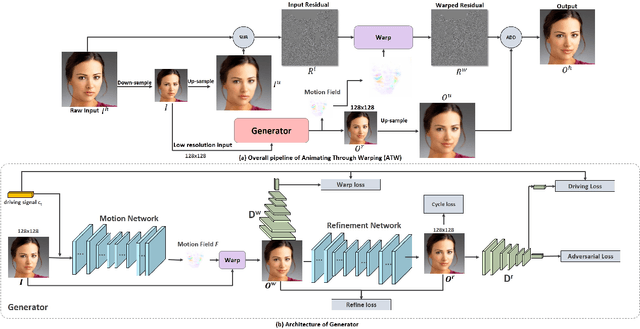
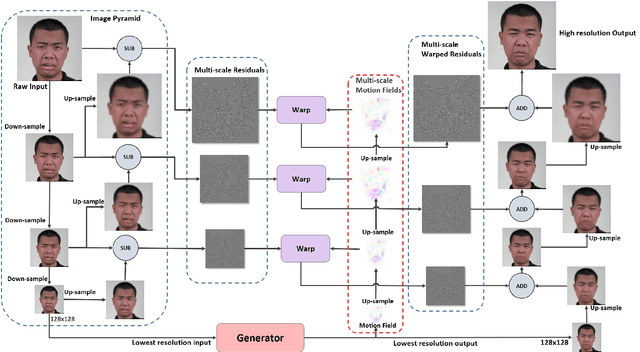


Advances in deep neural networks have considerably improved the art of animating a still image without operating in 3D domain. Whereas, prior arts can only animate small images (typically no larger than 512x512) due to memory limitations, difficulty of training and lack of high-resolution (HD) training datasets, which significantly reduce their potential for applications in movie production and interactive systems. Motivated by the idea that HD images can be generated by adding high-frequency residuals to low-resolution results produced by a neural network, we propose a novel framework known as Animating Through Warping (ATW) to enable efficient animation of HD images. Specifically, the proposed framework consists of two modules, a novel two-stage neural-network generator and a novel post-processing module known as Animating Through Warping (ATW). It only requires the generator to be trained on small images and can do inference on an image of any size. During inference, an HD input image is decomposed into a low-resolution component(128x128) and its corresponding high-frequency residuals. The generator predicts the low-resolution result as well as the motion field that warps the input face to the desired status (e.g., expressions categories or action units). Finally, the ResWarp module warps the residuals based on the motion field and adding the warped residuals to generates the final HD results from the naively up-sampled low-resolution results. Experiments show the effectiveness and efficiency of our method in generating high-resolution animations. Our proposed framework successfully animates a 4K facial image, which has never been achieved by prior neural models. In addition, our method generally guarantee the temporal coherency of the generated animations. Source codes will be made publicly available.
Contextual Residual Aggregation for Ultra High-Resolution Image Inpainting
May 19, 2020
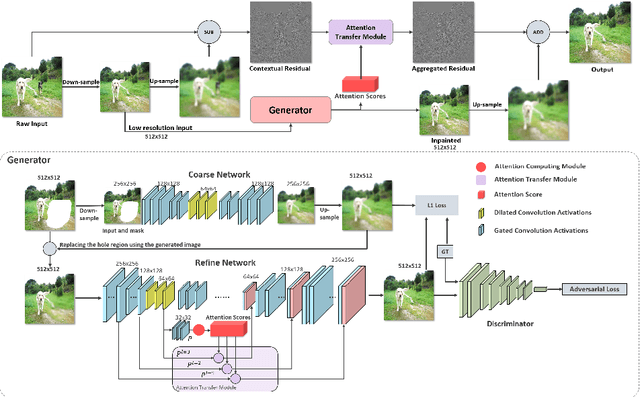


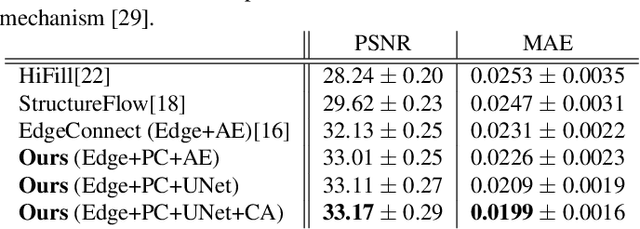
Recently data-driven image inpainting methods have made inspiring progress, impacting fundamental image editing tasks such as object removal and damaged image repairing. These methods are more effective than classic approaches, however, due to memory limitations they can only handle low-resolution inputs, typically smaller than 1K. Meanwhile, the resolution of photos captured with mobile devices increases up to 8K. Naive up-sampling of the low-resolution inpainted result can merely yield a large yet blurry result. Whereas, adding a high-frequency residual image onto the large blurry image can generate a sharp result, rich in details and textures. Motivated by this, we propose a Contextual Residual Aggregation (CRA) mechanism that can produce high-frequency residuals for missing contents by weighted aggregating residuals from contextual patches, thus only requiring a low-resolution prediction from the network. Since convolutional layers of the neural network only need to operate on low-resolution inputs and outputs, the cost of memory and computing power is thus well suppressed. Moreover, the need for high-resolution training datasets is alleviated. In our experiments, we train the proposed model on small images with resolutions 512x512 and perform inference on high-resolution images, achieving compelling inpainting quality. Our model can inpaint images as large as 8K with considerable hole sizes, which is intractable with previous learning-based approaches. We further elaborate on the light-weight design of the network architecture, achieving real-time performance on 2K images on a GTX 1080 Ti GPU. Codes are available at: Atlas200dk/sample-imageinpainting-HiFill.
DualGAN: Unsupervised Dual Learning for Image-to-Image Translation
Oct 09, 2018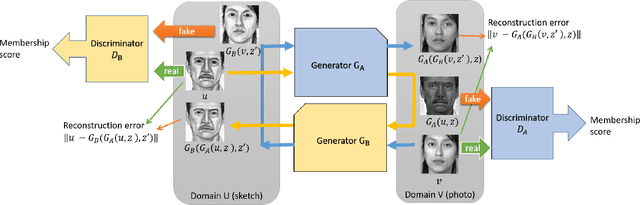
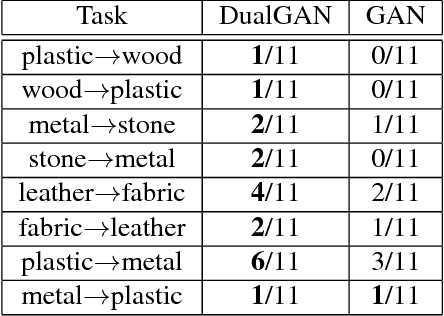

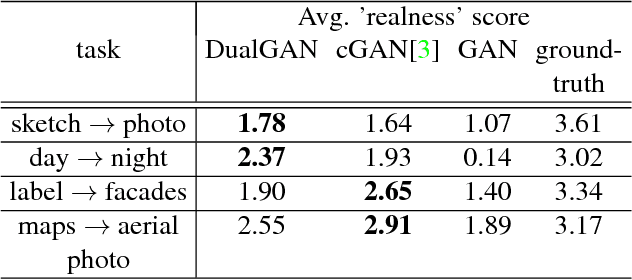
Conditional Generative Adversarial Networks (GANs) for cross-domain image-to-image translation have made much progress recently. Depending on the task complexity, thousands to millions of labeled image pairs are needed to train a conditional GAN. However, human labeling is expensive, even impractical, and large quantities of data may not always be available. Inspired by dual learning from natural language translation, we develop a novel dual-GAN mechanism, which enables image translators to be trained from two sets of unlabeled images from two domains. In our architecture, the primal GAN learns to translate images from domain U to those in domain V, while the dual GAN learns to invert the task. The closed loop made by the primal and dual tasks allows images from either domain to be translated and then reconstructed. Hence a loss function that accounts for the reconstruction error of images can be used to train the translators. Experiments on multiple image translation tasks with unlabeled data show considerable performance gain of DualGAN over a single GAN. For some tasks, DualGAN can even achieve comparable or slightly better results than conditional GAN trained on fully labeled data.
Branched Generative Adversarial Networks for Multi-Scale Image Manifold Learning
Mar 22, 2018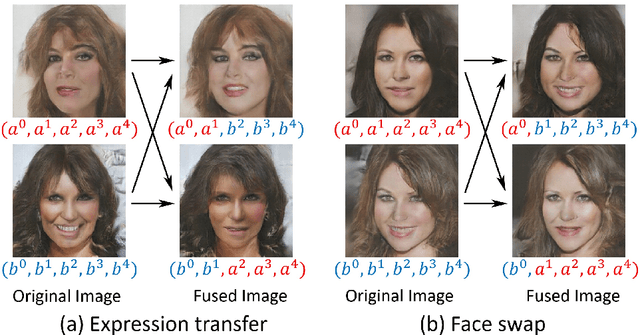
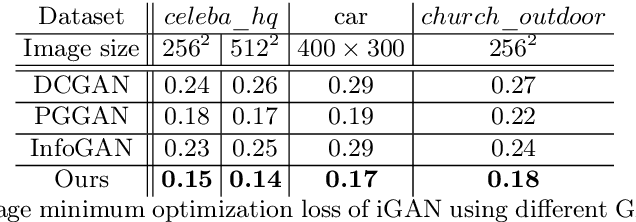
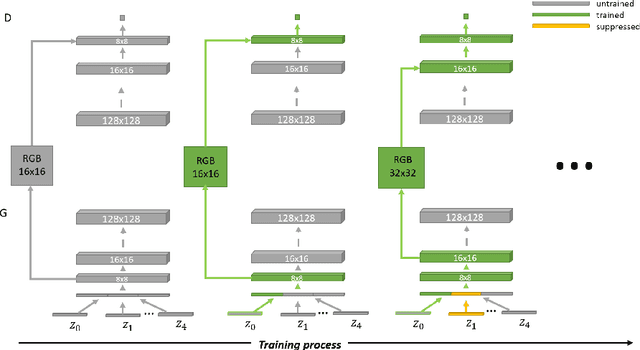
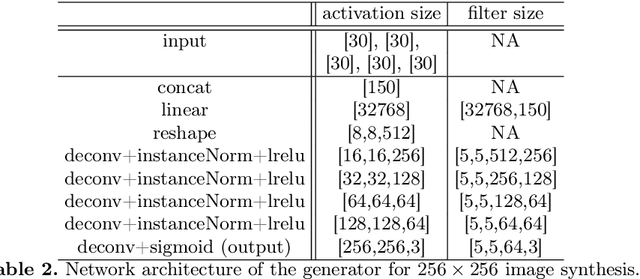
We introduce BranchGAN, a novel training method that enables unconditioned generative adversarial networks (GANs) to learn image manifolds at multiple scales. What is unique about BranchGAN is that it is trained in multiple branches, progressively covering both the breadth and depth of the network, as resolutions of the training images increase to reveal finer-scale features. Specifically, each noise vector, as input to the generator network, is explicitly split into several sub-vectors, each corresponding to and trained to learn image representations at a particular scale. During training, we progressively "de-freeze" the sub-vectors, one at a time, as a new set of higher-resolution images is employed for training and more network layers are added. A consequence of such an explicit sub-vector designation is that we can directly manipulate and even combine latent (sub-vector) codes that are associated with specific feature scales. Experiments demonstrate the effectiveness of our training method in multi-scale, disentangled learning of image manifolds and synthesis, without any extra labels and without compromising quality of the synthesized high-resolution images. We further demonstrate two new applications enabled by BranchGAN.