 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-Temporal Residual Aggregation for High Resolution Video Inpainting
Nov 05, 2021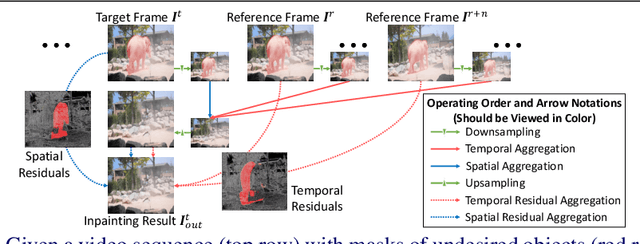
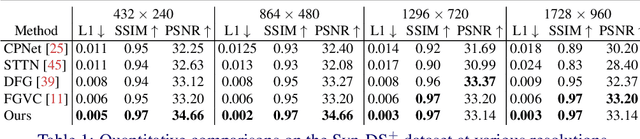
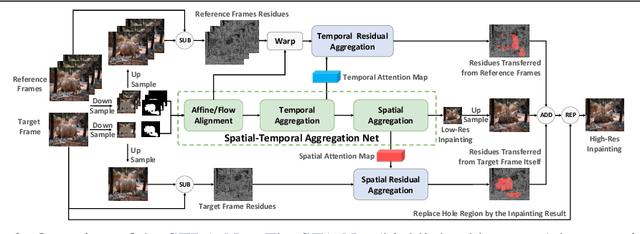
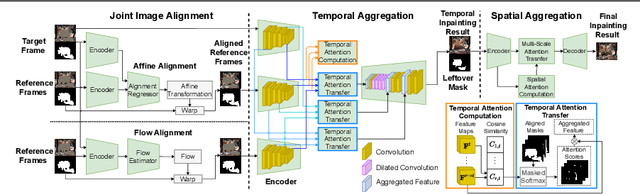
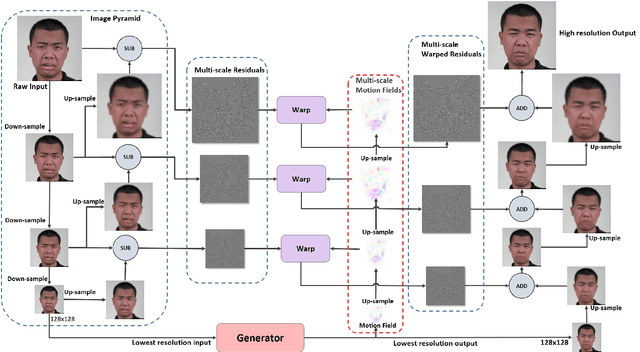
Recent learning-based inpainting algorithms have achieved compelling results for completing missing regions after removing undesired objects in videos. To maintain the temporal consistency among the frames, 3D spatial and temporal operations are often heavily used in the deep networks. However, these methods usually suffer from memory constraints and can only handle low resolution videos. We propose STRA-Net, a novel spatial-temporal residual aggregation framework for high resolution video inpainting. The key idea is to first learn and apply a spatial and temporal inpainting network on the downsampled low resolution videos. Then, we refine the low resolution results by aggregating the learned spatial and temporal image residuals (details) to the upsampled inpainted frames. Both the quantitative and qualitative evaluations show that we can produce more temporal-coherent and visually appealing results than the state-of-the-art methods on inpainting high resolution videos.
Animating Through Warping: an Efficient Method for High-Quality Facial Expression Animation
Aug 01, 2020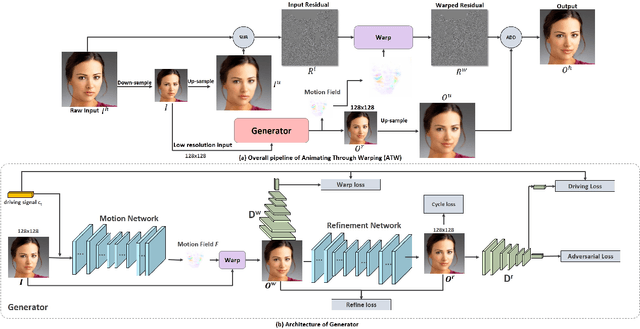


Advances in deep neural networks have considerably improved the art of animating a still image without operating in 3D domain. Whereas, prior arts can only animate small images (typically no larger than 512x512) due to memory limitations, difficulty of training and lack of high-resolution (HD) training datasets, which significantly reduce their potential for applications in movie production and interactive systems. Motivated by the idea that HD images can be generated by adding high-frequency residuals to low-resolution results produced by a neural network, we propose a novel framework known as Animating Through Warping (ATW) to enable efficient animation of HD images. Specifically, the proposed framework consists of two modules, a novel two-stage neural-network generator and a novel post-processing module known as Animating Through Warping (ATW). It only requires the generator to be trained on small images and can do inference on an image of any size. During inference, an HD input image is decomposed into a low-resolution component(128x128) and its corresponding high-frequency residuals. The generator predicts the low-resolution result as well as the motion field that warps the input face to the desired status (e.g., expressions categories or action units). Finally, the ResWarp module warps the residuals based on the motion field and adding the warped residuals to generates the final HD results from the naively up-sampled low-resolution results. Experiments show the effectiveness and efficiency of our method in generating high-resolution animations. Our proposed framework successfully animates a 4K facial image, which has never been achieved by prior neural models. In addition, our method generally guarantee the temporal coherency of the generated animations. Source codes will be made publicly available.