 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZihao Chen
CATCH: Context-based Meta Reinforcement Learning for Transferrable Architecture Search
Jul 18, 2020
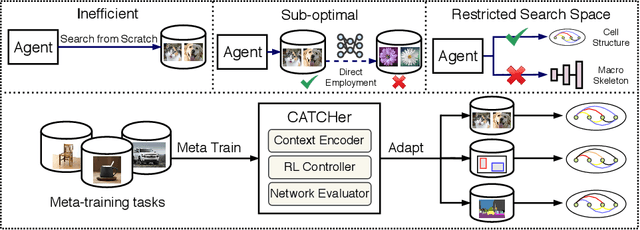
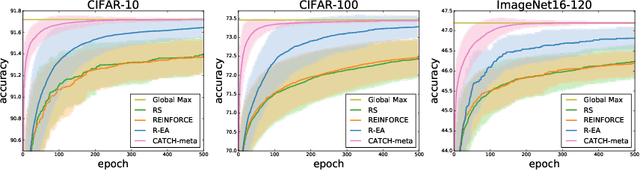
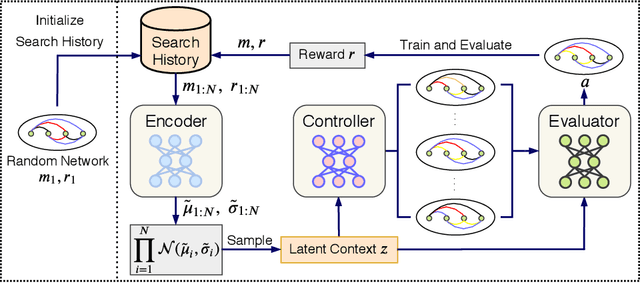
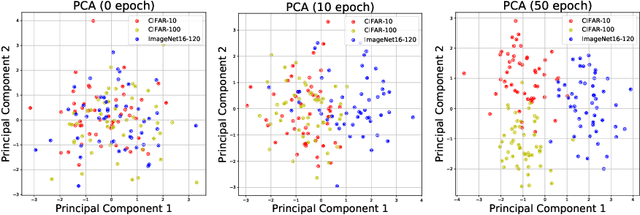
Neural Architecture Search (NAS) achieved many breakthroughs in recent years. In spite of its remarkable progress, many algorithms are restricted to particular search spaces. They also lack efficient mechanisms to reuse knowledge when confronting multiple tasks. These challenges preclude their applicability, and motivate our proposal of CATCH, a novel Context-bAsed meTa reinforcement learning (RL) algorithm for transferrable arChitecture searcH. The combination of meta-learning and RL allows CATCH to efficiently adapt to new tasks while being agnostic to search spaces. CATCH utilizes a probabilistic encoder to encode task properties into latent context variables, which then guide CATCH\textquoteright s controller to quickly "catch" top-performing networks. The contexts also assist a network evaluator in filtering inferior candidates and speed up learning. Extensive experiments demonstrate CATCH\textquoteright s universality and search efficiency over many other widely-recognized algorithms. It is also capable of handling cross-domain architecture search as competitive networks on ImageNet, COCO, and Cityscapes are identified. This is the first work to our knowledge that proposes an efficient transferrable NAS solution while maintaining robustness across various settings.
Accelerating Training using Tensor Decomposition
Sep 10, 2019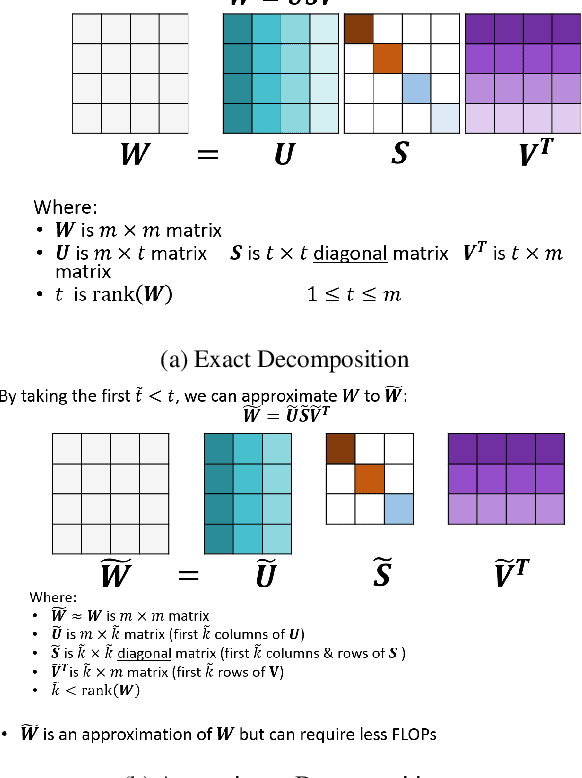
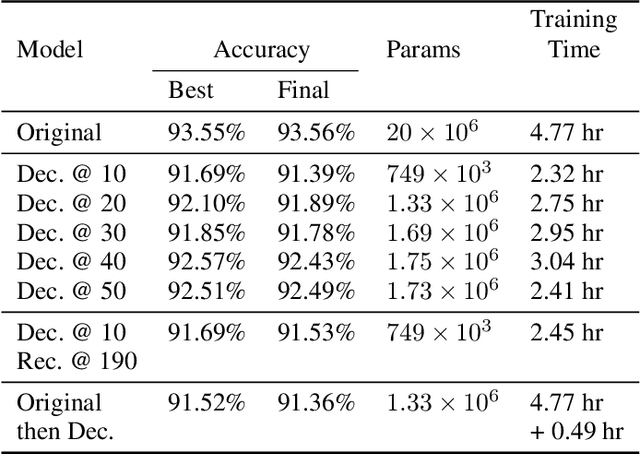
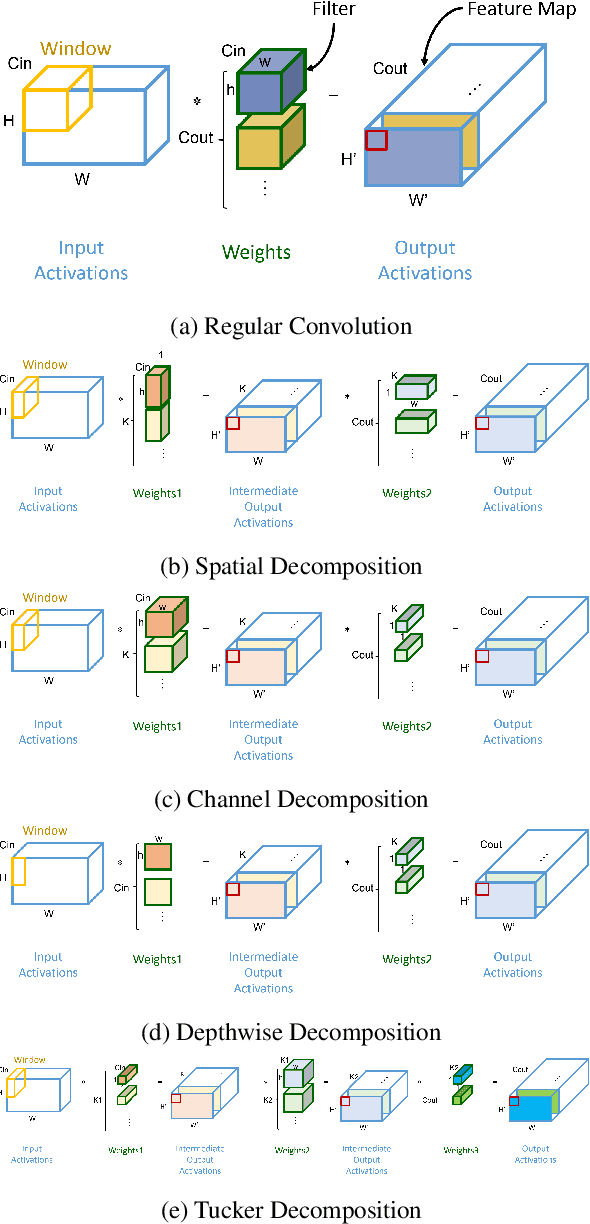
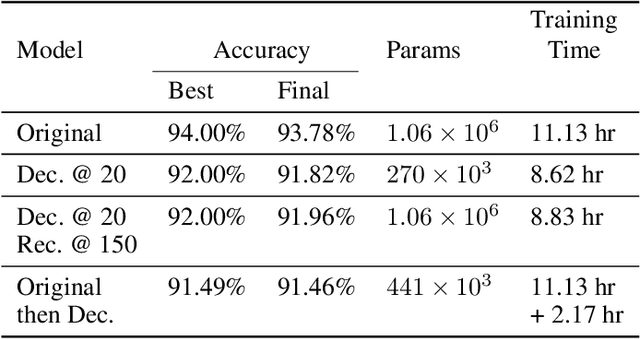
Tensor decomposition is one of the well-known approaches to reduce the latency time and number of parameters of a pre-trained model. However, in this paper, we propose an approach to use tensor decomposition to reduce training time of training a model from scratch. In our approach, we train the model from scratch (i.e., randomly initialized weights) with its original architecture for a small number of epochs, then the model is decomposed, and then continue training the decomposed model till the end. There is an optional step in our approach to convert the decomposed architecture back to the original architecture. We present results of using this approach on both CIFAR10 and Imagenet datasets, and show that there can be upto 2x speed up in training time with accuracy drop of upto 1.5% only, and in other cases no accuracy drop. This training acceleration approach is independent of hardware and is expected to have similar speed ups on both CPU and GPU platforms.
DeepShift: Towards Multiplication-Less Neural Networks
Jun 06, 2019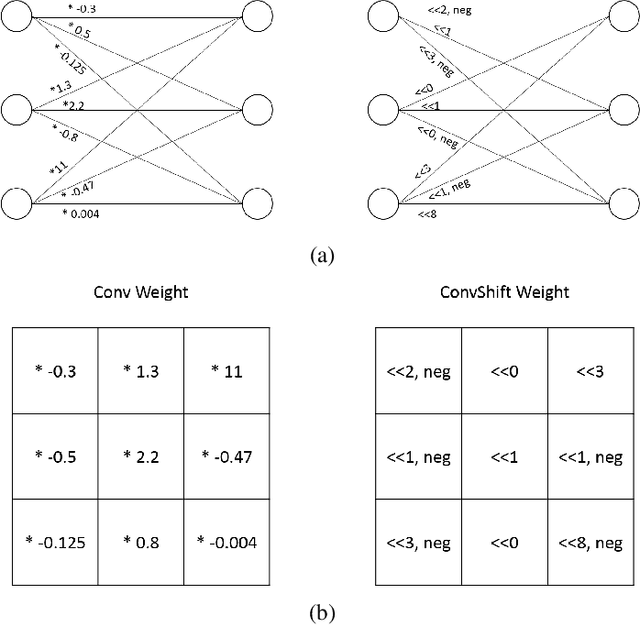
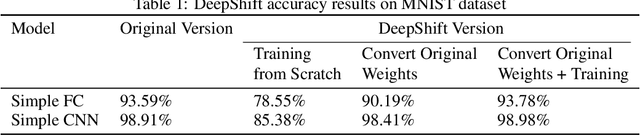
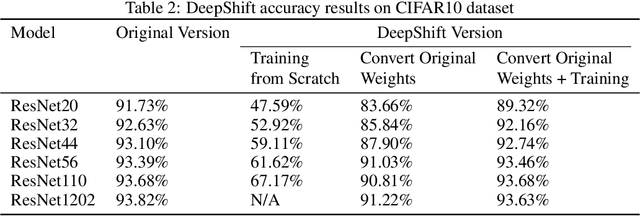
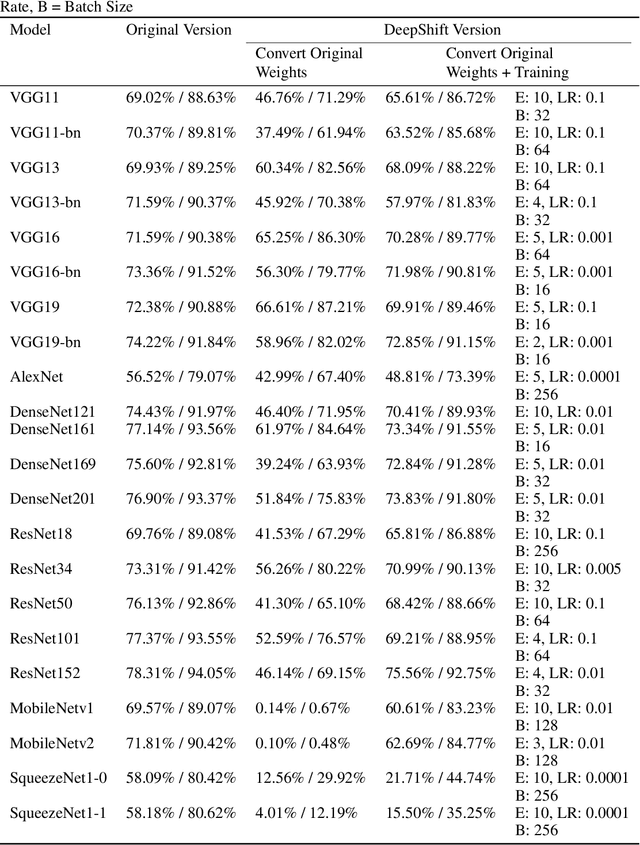
Deep learning models, especially DCNN have obtained high accuracies in several computer vision applications. However, for deployment in mobile environments, the high computation and power budget proves to be a major bottleneck. Convolution layers and fully connected layers, because of their intense use of multiplications, are the dominant contributer to this computation budget. This paper, proposes to tackle this problem by introducing two new operations: convolutional shifts and fully-connected shifts, that replace multiplications all together and use bitwise shift and bitwise negation instead. This family of neural network architectures (that use convolutional shifts and fully-connected shifts) are referred to as DeepShift models. With such DeepShift models that can be implemented with no multiplications, the authors have obtained accuracies of up to 93.6% on CIFAR10 dataset, and Top-1/Top-5 accuracies of 70.9%/90.13% on Imagenet dataset. Extensive testing is made on various well-known CNN architectures after converting all their convolution layers and fully connected layers to their bitwise shift counterparts, and we show that in some architectures, the Top-1 accuracy drops by less than 4% and the Top-5 accuracy drops by less than 1.5%. The experiments have been conducted on PyTorch framework and the code for training and running is submitted along with the paper and will be made available online.
Communication Lower Bounds for Distributed Convex Optimization: Partition Data on Features
Dec 02, 2016Recently, there has been an increasing interest in designing distributed convex optimization algorithms under the setting where the data matrix is partitioned on features. Algorithms under this setting sometimes have many advantages over those under the setting where data is partitioned on samples, especially when the number of features is huge. Therefore, it is important to understand the inherent limitations of these optimization problems. In this paper, with certain restrictions on the communication allowed in the procedures, we develop tight lower bounds on communication rounds for a broad class of non-incremental algorithms under this setting. We also provide a lower bound on communication rounds for a class of (randomized) incremental algorithms.
A Proximal Stochastic Quasi-Newton Algorithm
Nov 16, 2016In this paper, we discuss the problem of minimizing the sum of two convex functions: a smooth function plus a non-smooth function. Further, the smooth part can be expressed by the average of a large number of smooth component functions, and the non-smooth part is equipped with a simple proximal mapping. We propose a proximal stochastic second-order method, which is efficient and scalable. It incorporates the Hessian in the smooth part of the function and exploits multistage scheme to reduce the variance of the stochastic gradient. We prove that our method can achieve linear rate of convergence.