 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Hierarchical Framework for Fine-grained Cross-view Geo-localization over Large-scale Scenarios
May 12, 2025Cross-view geo-localization is a promising solution for large-scale localization problems, requiring the sequential execution of retrieval and metric localization tasks to achieve fine-grained predictions. However, existing methods typically focus on designing standalone models for these two tasks, resulting in inefficient collaboration and increased training overhead. In this paper, we propose UnifyGeo, a novel unified hierarchical geo-localization framework that integrates retrieval and metric localization tasks into a single network. Specifically, we first employ a unified learning strategy with shared parameters to jointly learn multi-granularity representation, facilitating mutual reinforcement between these two tasks. Subsequently, we design a re-ranking mechanism guided by a dedicated loss function, which enhances geo-localization performance by improving both retrieval accuracy and metric localization references. Extensive experiments demonstrate that UnifyGeo significantly outperforms the state-of-the-arts in both task-isolated and task-associated settings. Remarkably, on the challenging VIGOR benchmark, which supports fine-grained localization evaluation, the 1-meter-level localization recall rate improves from 1.53\% to 39.64\% and from 0.43\% to 25.58\% under same-area and cross-area evaluations, respectively. Code will be made publicly available.
Pack-PTQ: Advancing Post-training Quantization of Neural Networks by Pack-wise Reconstruction
May 01, 2025Post-training quantization (PTQ) has evolved as a prominent solution for compressing complex models, which advocates a small calibration dataset and avoids end-to-end retraining. However, most existing PTQ methods employ block-wise reconstruction, which neglects cross-block dependency and exhibits a notable accuracy drop in low-bit cases. To address these limitations, this paper presents a novel PTQ method, dubbed Pack-PTQ. First, we design a Hessian-guided adaptive packing mechanism to partition blocks into non-overlapping packs, which serve as the base unit for reconstruction, thereby preserving the cross-block dependency and enabling accurate quantization parameters estimation. Second, based on the pack configuration, we propose a mixed-precision quantization approach to assign varied bit-widths to packs according to their distinct sensitivities, thereby further enhancing performance. Extensive experiments on 2D image and 3D point cloud classification tasks, using various network architectures, demonstrate the superiority of our method over the state-of-the-art PTQ methods.
STAG: Enabling Low Latency and Low Staleness of GNN-based Services with Dynamic Graphs
Sep 27, 2023Many emerging user-facing services adopt Graph Neural Networks (GNNs) to improve serving accuracy. When the graph used by a GNN model changes, representations (embedding) of nodes in the graph should be updated accordingly. However, the node representation update is too slow, resulting in either long response latency of user queries (the inference is performed after the update completes) or high staleness problem (the inference is performed based on stale data). Our in-depth analysis shows that the slow update is mainly due to neighbor explosion problem in graphs and duplicated computation. Based on such findings, we propose STAG, a GNN serving framework that enables low latency and low staleness of GNN-based services. It comprises a collaborative serving mechanism and an additivity-based incremental propagation strategy. With the collaborative serving mechanism, only part of node representations are updated during the update phase, and the final representations are calculated in the inference phase. It alleviates the neighbor explosion problem. The additivity-based incremental propagation strategy reuses intermediate data during the update phase, eliminating duplicated computation problem. Experimental results show that STAG accelerates the update phase by 1.3x~90.1x, and greatly reduces staleness time with a slight increase in response latency.
Dense Semantic 3D Map Based Long-Term Visual Localization with Hybrid Features
May 21, 2020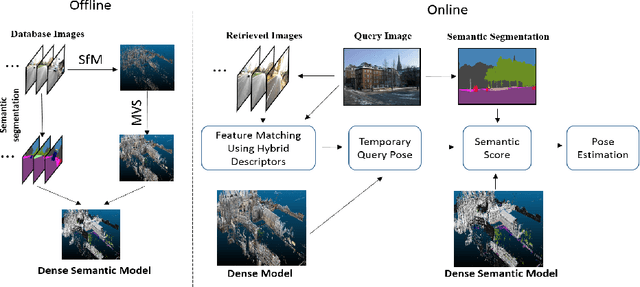
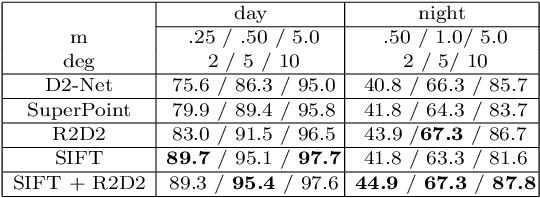

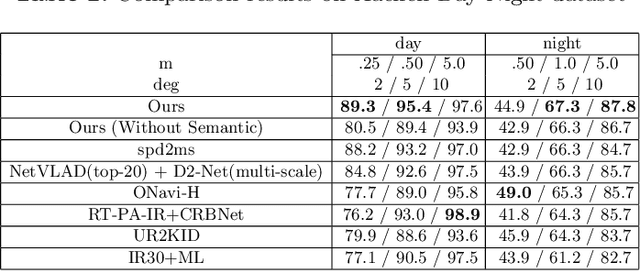
Visual localization plays an important role in many applications. However, due to the large appearance variations such as season and illumination changes, as well as weather and day-night variations, it's still a big challenge for robust long-term visual localization algorithms. In this paper, we present a novel visual localization method using hybrid handcrafted and learned features with dense semantic 3D map. Hybrid features help us to make full use of their strengths in different imaging conditions, and the dense semantic map provide us reliable and complete geometric and semantic information for constructing sufficient 2D-3D matching pairs with semantic consistency scores. In our pipeline, we retrieve and score each candidate database image through the semantic consistency between the dense model and the query image. Then the semantic consistency score is used as a soft constraint in the weighted RANSAC-based PnP pose solver. Experimental results on long-term visual localization benchmarks demonstrate the effectiveness of our method compared with state-of-the-arts.