 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidence-based Decision Modeling for Synthetic Face Detection with Uncertainty-driven Active Learning
May 11, 2026With the rapid development of deep generative models, forged facial images are massively exploited for illegal activities. Although existing synthetic face detection methods have achieved significant progress, they suffer from the inherent limitation of overconfidence due to their reliance on the Softmax activation function. Thus, these methods often lead to unreliable predictions when encountering unknown Out-of-Distribution (OOD) images, and cannot ascertain the model's uncertainty in its prediction. Meanwhile, most existing methods require massive high-quality annotated data, which greatly limits their practicability across diverse scenarios. To address these limitations, we propose EMSFD (Evidence-based decision Modeling for Synthetic Face Detection with uncertainty-driven active learning), an approach designed to enhance detection reliability and generalizability. Specifically, EMSFD models class evidence using the Dirichlet distribution and explicitly incorporates model uncertainty into the prediction process. Furthermore, during training, the estimated uncertainty is exploited to prioritize more informative samples from the unlabeled pool for annotation, thereby reducing labeling cost and improving model generalization. Extensive experimental evaluations demonstrate that our method enhances the interpretability of synthetic face detection. Meanwhile, our method yields a 15\% increase in accuracy compared to existing state-of-the-art (SOTA) baselines, which demonstrates the superior detection performance and generalizability of our approach. Our code is available at: https://github.com/hzx111621/EMSFD.
Only Train Once: Uncertainty-Aware One-Class Learning for Face Authenticity Detection
May 11, 2026The rapid evolution of generative paradigms has enabled the creation of highly realistic imagery, which escalating the risks of identity fraud and the dissemination of disinformation. Most existing approaches frame face forgery detection as a fully supervised binary classification problem. Consequently, these models typically exhibit significant performance decay when tasked with detecting forgeries from previously unseen generative paradigms. Furthermore, these methods focus exclusively on either DeepFakes or fully synthesized faces, thereby failing to provide a generalized framework for universal face forgery detection. In this paper, we address this challenge by introducing FADNet (Face Authenticity Detector Net), % a self-supervised framework that which reformulates face forgery detection as a one-class classification (OCC) task. By training exclusively on authentic facial data to capture their intrinsic representations, FADNet flags any image whose feature embedding deviates significantly from the learned distribution of real faces as a forgery. The framework incorporates Evidential Deep Learning (EDL) to quantify predictive uncertainty and utilizes a plug-and-play pseudo-forgery image generator (PFIG) to tighten decision boundaries around authentic data. Extensive experimental evaluations on the DF40 and ASFD benchmarks demonstrate that FADNet achieves superior performance and generalization capabilities. Specifically, FADNet substantially outperforms existing state-of-the-art (SOTA) methods, yielding a remarkable average accuracy of 96.63\% and an average precision of 98.83\%.
Model Discrepancy Learning: Synthetic Faces Detection Based on Multi-Reconstruction
Apr 10, 2025



Advances in image generation enable hyper-realistic synthetic faces but also pose risks, thus making synthetic face detection crucial. Previous research focuses on the general differences between generated images and real images, often overlooking the discrepancies among various generative techniques. In this paper, we explore the intrinsic relationship between synthetic images and their corresponding generation technologies. We find that specific images exhibit significant reconstruction discrepancies across different generative methods and that matching generation techniques provide more accurate reconstructions. Based on this insight, we propose a Multi-Reconstruction-based detector. By reversing and reconstructing images using multiple generative models, we analyze the reconstruction differences among real, GAN-generated, and DM-generated images to facilitate effective differentiation. Additionally, we introduce the Asian Synthetic Face Dataset (ASFD), containing synthetic Asian faces generated with various GANs and DMs. This dataset complements existing synthetic face datasets. Experimental results demonstrate that our detector achieves exceptional performance, with strong generalization and robustness.
HaluEval-Wild: Evaluating Hallucinations of Language Models in the Wild
Mar 07, 2024Hallucinations pose a significant challenge to the reliability of large language models (LLMs) in critical domains. Recent benchmarks designed to assess LLM hallucinations within conventional NLP tasks, such as knowledge-intensive question answering (QA) and summarization, are insufficient for capturing the complexities of user-LLM interactions in dynamic, real-world settings. To address this gap, we introduce HaluEval-Wild, the first benchmark specifically designed to evaluate LLM hallucinations in the wild. We meticulously collect challenging (adversarially filtered by Alpaca) user queries from existing real-world user-LLM interaction datasets, including ShareGPT, to evaluate the hallucination rates of various LLMs. Upon analyzing the collected queries, we categorize them into five distinct types, which enables a fine-grained analysis of the types of hallucinations LLMs exhibit, and synthesize the reference answers with the powerful GPT-4 model and retrieval-augmented generation (RAG). Our benchmark offers a novel approach towards enhancing our comprehension and improvement of LLM reliability in scenarios reflective of real-world interactions.
GSCLIP : A Framework for Explaining Distribution Shifts in Natural Language
Jun 30, 2022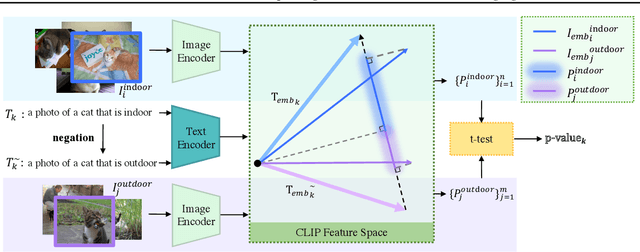
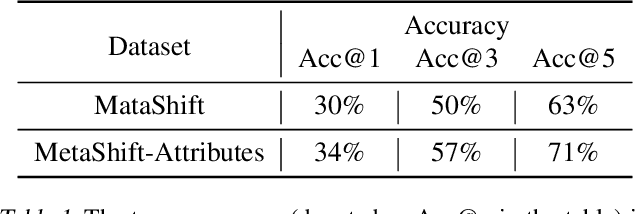
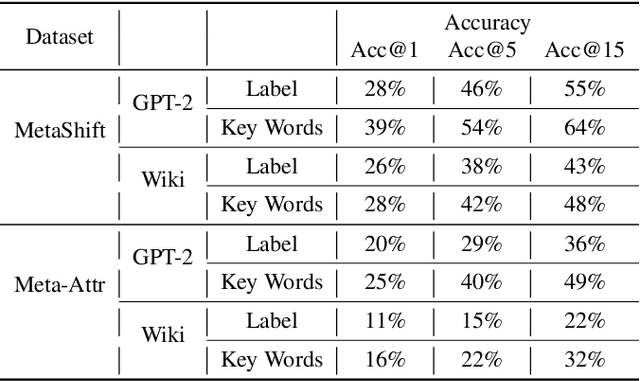
Helping end users comprehend the abstract distribution shifts can greatly facilitate AI deployment. Motivated by this, we propose a novel task, dataset explanation. Given two image data sets, dataset explanation aims to automatically point out their dataset-level distribution shifts with natural language. Current techniques for monitoring distribution shifts provide inadequate information to understand datasets with the goal of improving data quality. Therefore, we introduce GSCLIP, a training-free framework to solve the dataset explanation task. In GSCLIP, we propose the selector as the first quantitative evaluation method to identify explanations that are proper to summarize dataset shifts. Furthermore, we leverage this selector to demonstrate the superiority of a generator based on language model generation. Systematic evaluation on natural data shift verifies that GSCLIP, a combined system of a hybrid generator group and an efficient selector is not only easy-to-use but also powerful for dataset explanation at scale.
Learning the Beauty in Songs: Neural Singing Voice Beautifier
Mar 02, 2022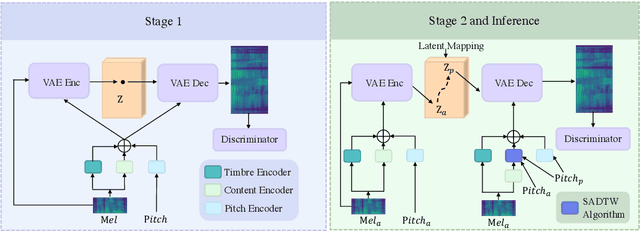
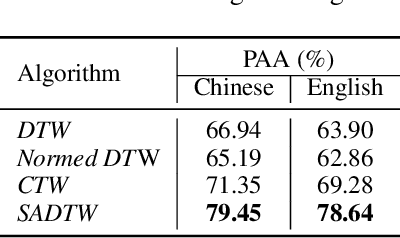
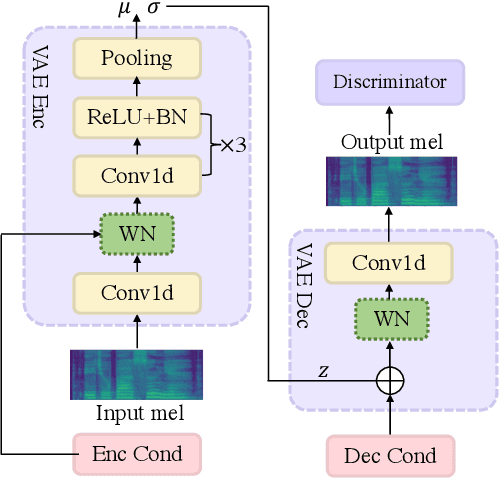

We are interested in a novel task, singing voice beautifying (SVB). Given the singing voice of an amateur singer, SVB aims to improve the intonation and vocal tone of the voice, while keeping the content and vocal timbre. Current automatic pitch correction techniques are immature, and most of them are restricted to intonation but ignore the overall aesthetic quality. Hence, we introduce Neural Singing Voice Beautifier (NSVB), the first generative model to solve the SVB task, which adopts a conditional variational autoencoder as the backbone and learns the latent representations of vocal tone. In NSVB, we propose a novel time-warping approach for pitch correction: Shape-Aware Dynamic Time Warping (SADTW), which ameliorates the robustness of existing time-warping approaches, to synchronize the amateur recording with the template pitch curve. Furthermore, we propose a latent-mapping algorithm in the latent space to convert the amateur vocal tone to the professional one. To achieve this, we also propose a new dataset containing parallel singing recordings of both amateur and professional versions. Extensive experiments on both Chinese and English songs demonstrate the effectiveness of our methods in terms of both objective and subjective metrics. Audio samples are available at~\url{https://neuralsvb.github.io}. Codes: \url{https://github.com/MoonInTheRiver/NeuralSVB}.
High-Speed and High-Quality Text-to-Lip Generation
Jul 14, 2021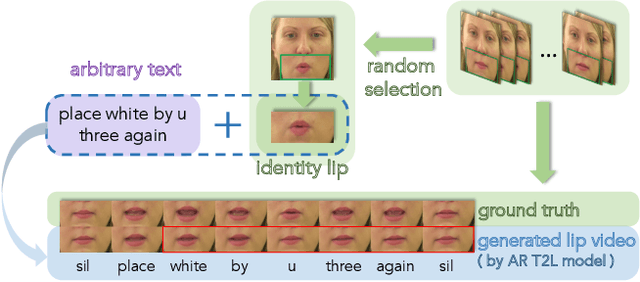
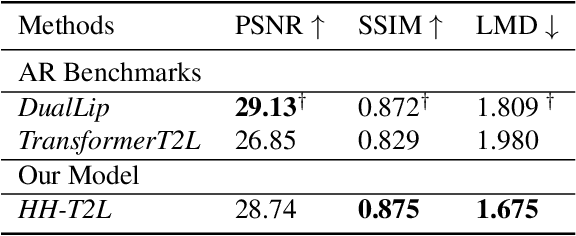
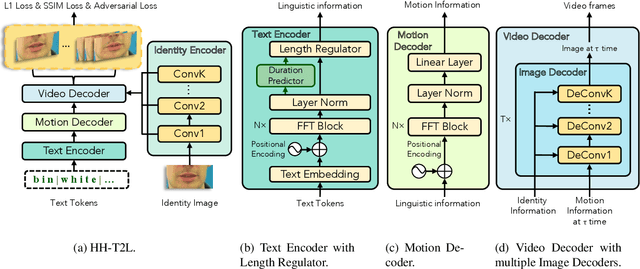
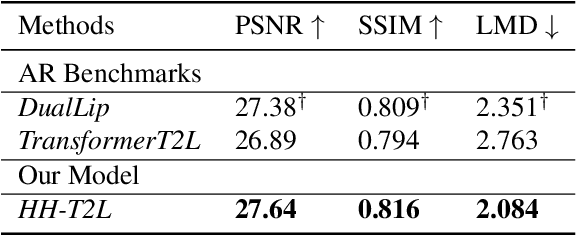
As a key component of talking face generation, lip movements generation determines the naturalness and coherence of the generated talking face video. Prior literature mainly focuses on speech-to-lip generation while there is a paucity in text-to-lip (T2L) generation. T2L is a challenging task and existing end-to-end works depend on the attention mechanism and autoregressive (AR) decoding manner. However, the AR decoding manner generates current lip frame conditioned on frames generated previously, which inherently hinders the inference speed, and also has a detrimental effect on the quality of generated lip frames due to error propagation. This encourages the research of parallel T2L generation. In this work, we propose a novel parallel decoding model for high-speed and high-quality text-to-lip generation (HH-T2L). Specifically, we predict the duration of the encoded linguistic features and model the target lip frames conditioned on the encoded linguistic features with their duration in a non-autoregressive manner. Furthermore, we incorporate the structural similarity index loss and adversarial learning to improve perceptual quality of generated lip frames and alleviate the blurry prediction problem. Extensive experiments conducted on GRID and TCD-TIMIT datasets show that 1) HH-T2L generates lip movements with competitive quality compared with the state-of-the-art AR T2L model DualLip and exceeds the baseline AR model TransformerT2L by a notable margin benefiting from the mitigation of the error propagation problem; and 2) exhibits distinct superiority in inference speed (an average speedup of 19$\times$ than DualLip on TCD-TIMIT).