 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPA-RAM: Grasp-Pretraining Augmented Robotic Attention Mamba for Spatial Task Learning
Apr 28, 2025



Most existing robot manipulation methods prioritize task learning by enhancing perception through complex deep network architectures. However, they face challenges in real-time collision-free planning. Hence, Robotic Attention Mamba (RAM) is designed for refined planning. Specifically, by integrating Mamba and parallel single-view attention, RAM aligns multi-view vision and task-related language features, ensuring efficient fine-grained task planning with linear complexity and robust real-time performance. Nevertheless, it has the potential for further improvement in high-precision grasping and manipulation. Thus, Grasp-Pretraining Augmentation (GPA) is devised, with a grasp pose feature extractor pretrained utilizing object grasp poses directly inherited from whole-task demonstrations. Subsequently, the extracted grasp features are fused with the spatially aligned planning features from RAM through attention-based Pre-trained Location Fusion, preserving high-resolution grasping cues overshadowed by an overemphasis on global planning. To summarize, we propose Grasp-Pretraining Augmented Robotic Attention Mamba (GPA-RAM), dividing spatial task learning into RAM for planning skill learning and GPA for grasping skill learning. GPA-RAM demonstrates superior performance across three robot systems with distinct camera configurations in simulation and the real world. Compared with previous state-of-the-art methods, it improves the absolute success rate by 8.2% (from 79.3% to 87.5%) on the RLBench multi-task benchmark and 40\% (from 16% to 56%), 12% (from 86% to 98%) on the ALOHA bimanual manipulation tasks, while delivering notably faster inference. Furthermore, experimental results demonstrate that both RAM and GPA enhance task learning, with GPA proving robust to different architectures of pretrained grasp pose feature extractors. The website is: https://logssim.github.io/GPA\_RAM\_website/.
Improving Semantic Analysis on Point Clouds via Auxiliary Supervision of Local Geometric Priors
Jan 14, 2020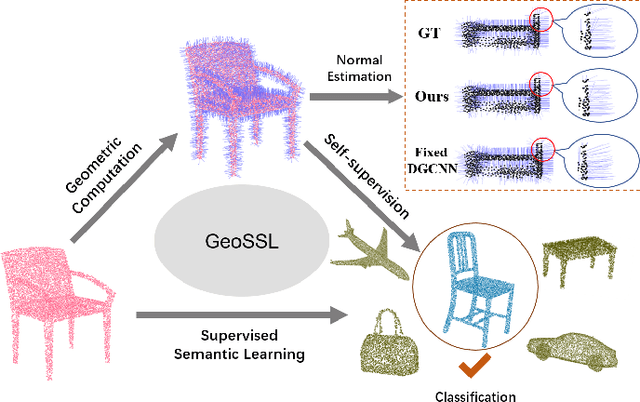
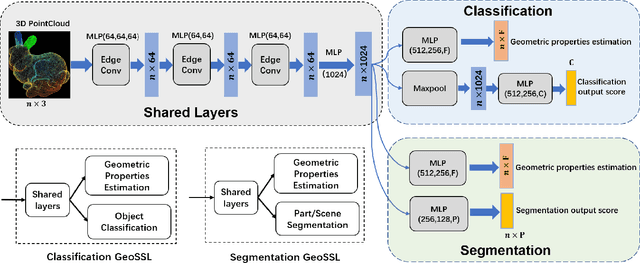
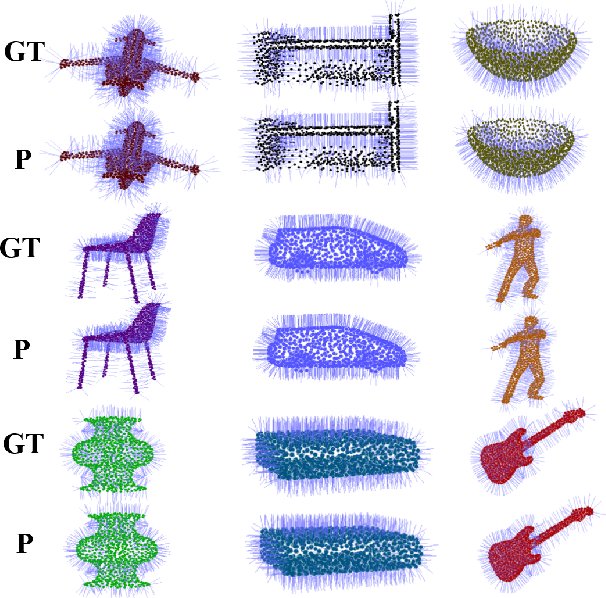
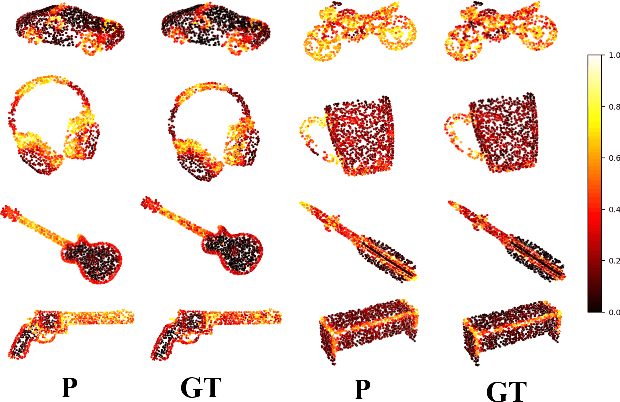
Existing deep learning algorithms for point cloud analysis mainly concern discovering semantic patterns from global configuration of local geometries in a supervised learning manner. However, very few explore geometric properties revealing local surface manifolds embedded in 3D Euclidean space to discriminate semantic classes or object parts as additional supervision signals. This paper is the first attempt to propose a unique multi-task geometric learning network to improve semantic analysis by auxiliary geometric learning with local shape properties, which can be either generated via physical computation from point clouds themselves as self-supervision signals or provided as privileged information. Owing to explicitly encoding local shape manifolds in favor of semantic analysis, the proposed geometric self-supervised and privileged learning algorithms can achieve superior performance to their backbone baselines and other state-of-the-art methods, which are verified in the experiments on the popular benchmarks.
Concise and Effective Network for 3D Human Modeling from Orthogonal Silhouettes
Dec 25, 2019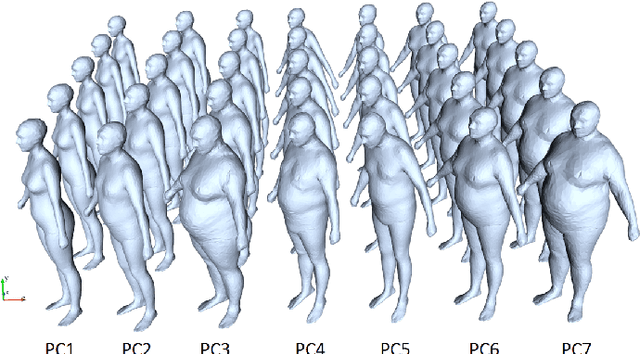
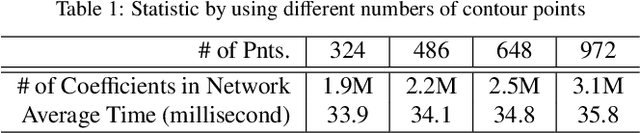
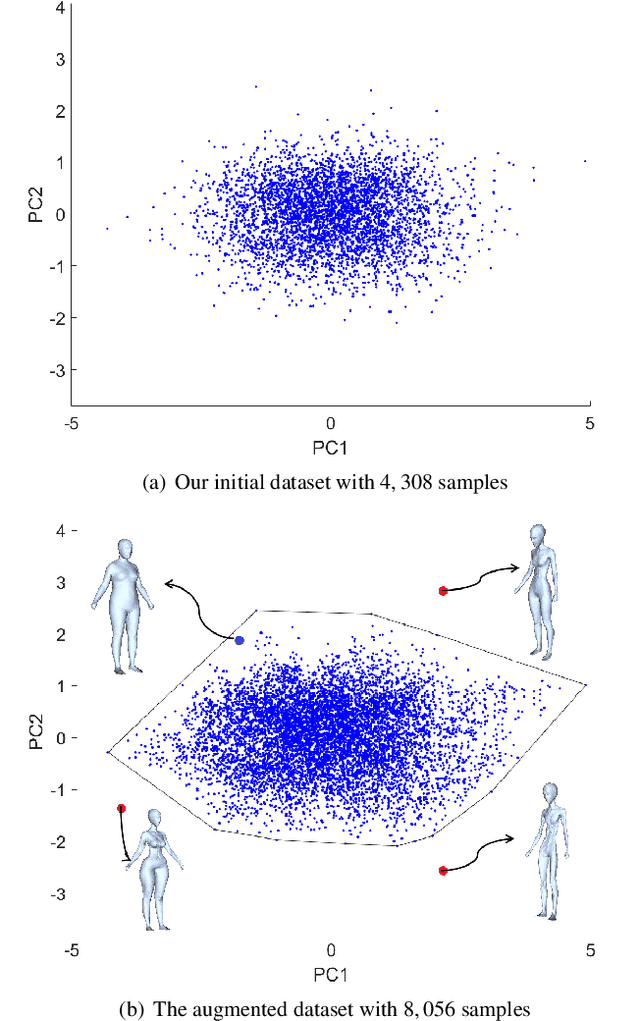
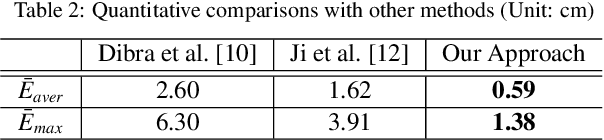
In this paper, we revisit the problem of 3D human modeling from two orthogonal silhouettes of individuals (i.e., front and side views). Different from our prior work, a supervised learning approach based on \textit{convolutional neural network} (CNN) is investigated to solve the problem by establishing a mapping function that can effectively extract features from two silhouettes and fuse them into coefficients in the shape space of human bodies. A new CNN structure is proposed in our work to exact not only the discriminative features of front and side views and also their mixed features for the mapping function. 3D human models with high accuracy are synthesized from coefficients generated by the mapping function. Existing CNN approaches for 3D human modeling usually learn a large number of parameters (from 8M to 350M) from two binary images. Differently, we investigate a new network architecture and conduct the samples on silhouettes as input. As a consequence, more accurate models can be generated by our network with only 2.5M coefficients. The training of our network is conducted on samples obtained by augmenting a publicly accessible dataset. Learning transfer by using datasets with a smaller number of scanned models is applied to our network to enable the function of generating results with gender-oriented (or geographical) patterns.
A Weight-coded Evolutionary Algorithm for the Multidimensional Knapsack Problem
Apr 01, 2015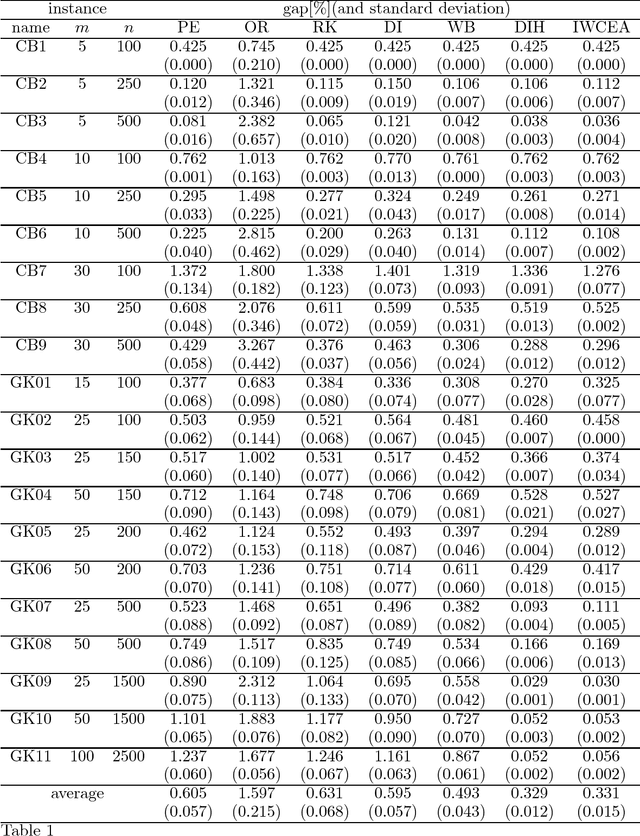
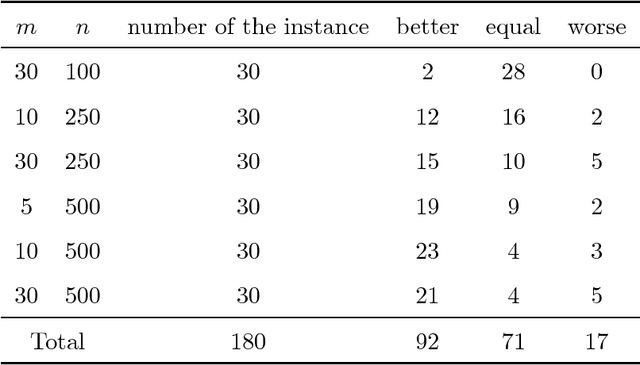
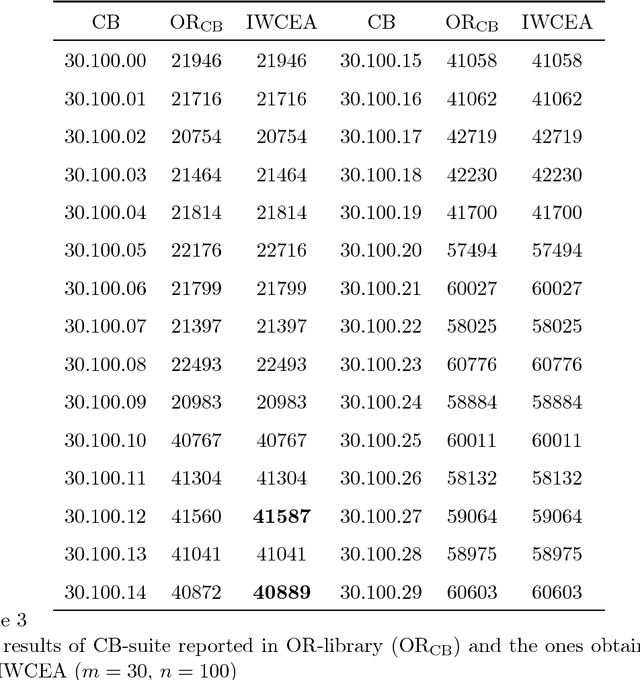
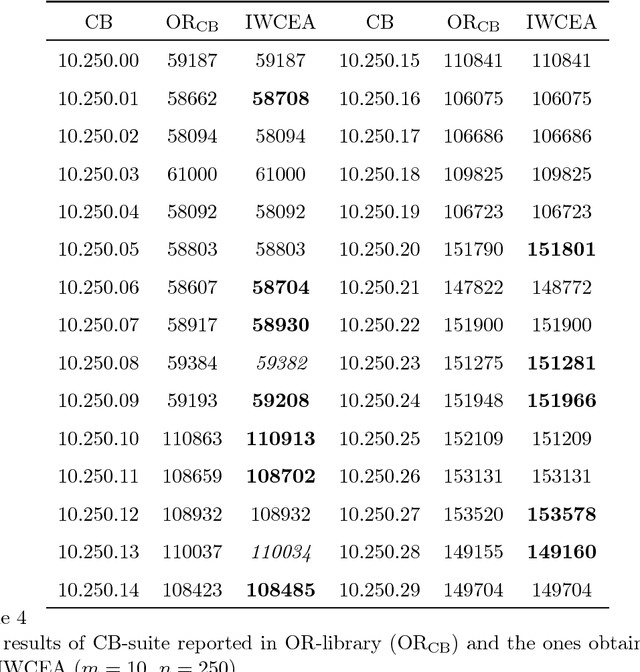
A revised weight-coded evolutionary algorithm (RWCEA) is proposed for solving multidimensional knapsack problems. This RWCEA uses a new decoding method and incorporates a heuristic method in initialization. Computational results show that the RWCEA performs better than a weight-coded evolutionary algorithm proposed by Raidl (1999) and to some existing benchmarks, it can yield better results than the ones reported in the OR-library.
On the performance of a hybrid genetic algorithm in dynamic environments
Mar 08, 2013
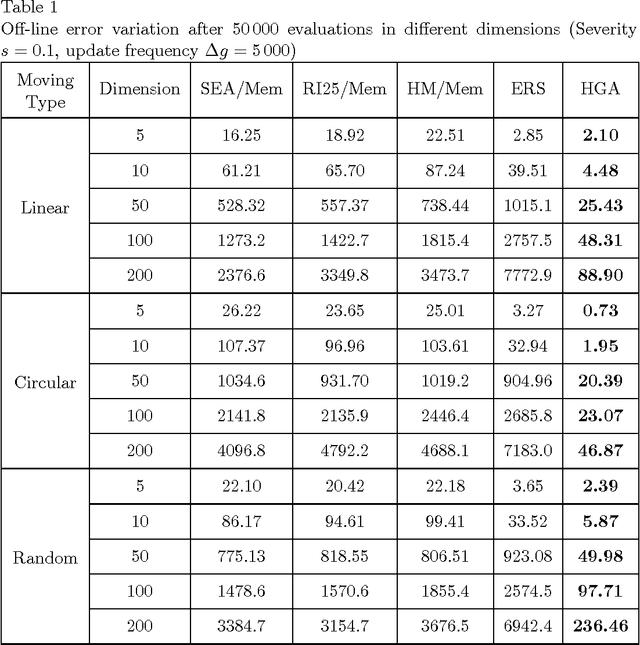
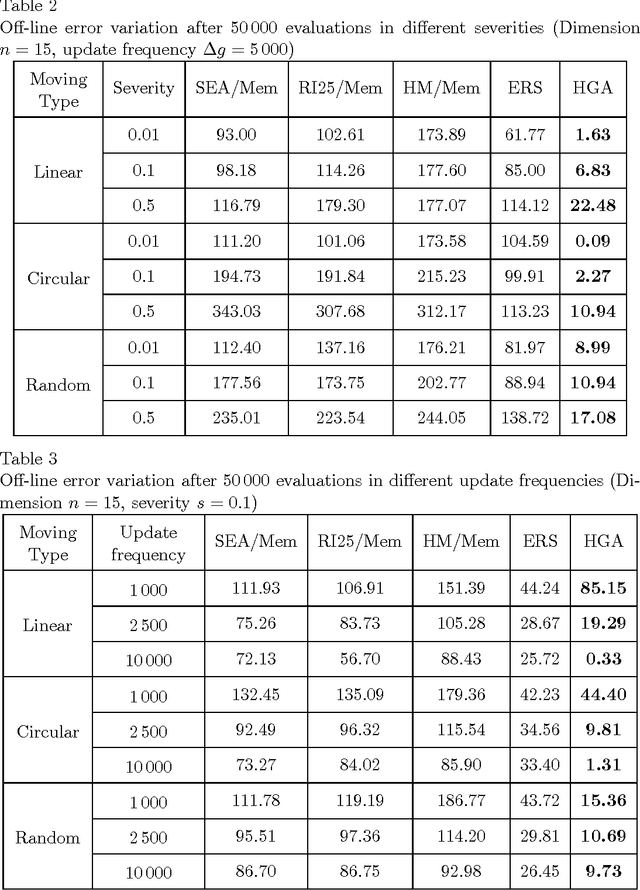
The ability to track the optimum of dynamic environments is important in many practical applications. In this paper, the capability of a hybrid genetic algorithm (HGA) to track the optimum in some dynamic environments is investigated for different functional dimensions, update frequencies, and displacement strengths in different types of dynamic environments. Experimental results are reported by using the HGA and some other existing evolutionary algorithms in the literature. The results show that the HGA has better capability to track the dynamic optimum than some other existing algorithms.
* This paper has been submitted to Applied Mathematics and Computation on May 22, 2012 Revised version has been submitted to Applied Mathematics and Computation on March 1, 2013