 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-stage Audio-Visual Target Speaker Extraction System for Real-Time Processing On Edge Device
May 28, 2025Audio-Visual Target Speaker Extraction (AVTSE) aims to isolate a target speaker's voice in a multi-speaker environment with visual cues as auxiliary. Most of the existing AVTSE methods encode visual and audio features simultaneously, resulting in extremely high computational complexity and making it impractical for real-time processing on edge devices. To tackle this issue, we proposed a two-stage ultra-compact AVTSE system. Specifically, in the first stage, a compact network is employed for voice activity detection (VAD) using visual information. In the second stage, the VAD results are combined with audio inputs to isolate the target speaker's voice. Experiments show that the proposed system effectively suppresses background noise and interfering voices while spending little computational resources.
Unsupervised Learning for Large-Scale Fiber Detection and Tracking in Microscopic Material Images
May 25, 2018
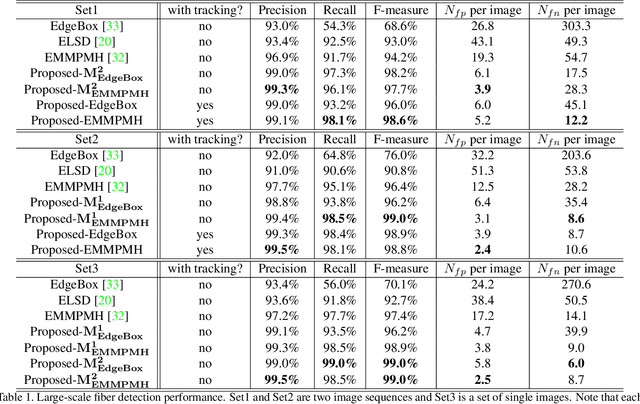
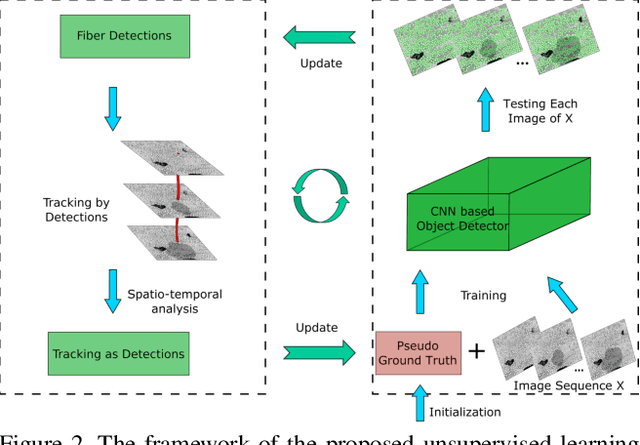
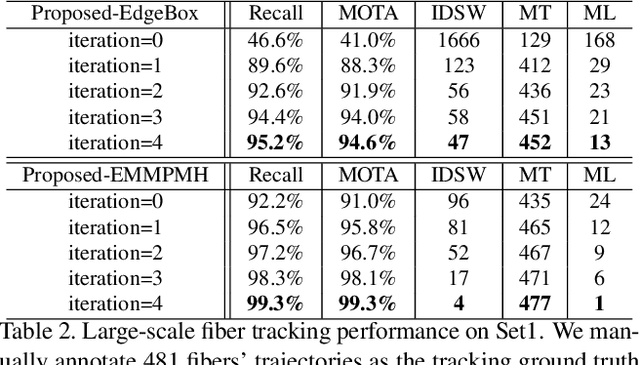
Constructing 3D structures from serial section data is a long standing problem in microscopy. The structure of a fiber reinforced composite material can be reconstructed using a tracking-by-detection model. Tracking-by-detection algorithms rely heavily on detection accuracy, especially the recall performance. The state-of-the-art fiber detection algorithms perform well under ideal conditions, but are not accurate where there are local degradations of image quality, due to contaminants on the material surface and/or defocus blur. Convolutional Neural Networks (CNN) could be used for this problem, but would require a large number of manual annotated fibers, which are not available. We propose an unsupervised learning method to accurately detect fibers on the large scale, that is robust against local degradations of image quality. The proposed method does not require manual annotations, but uses fiber shape/size priors and spatio-temporal consistency in tracking to simulate the supervision in the training of the CNN. Experiments show significant improvements over state-of-the-art fiber detection algorithms together with advanced tracking performance.